Astera Centerprise – What’s New in Version 7 and Version 8¶
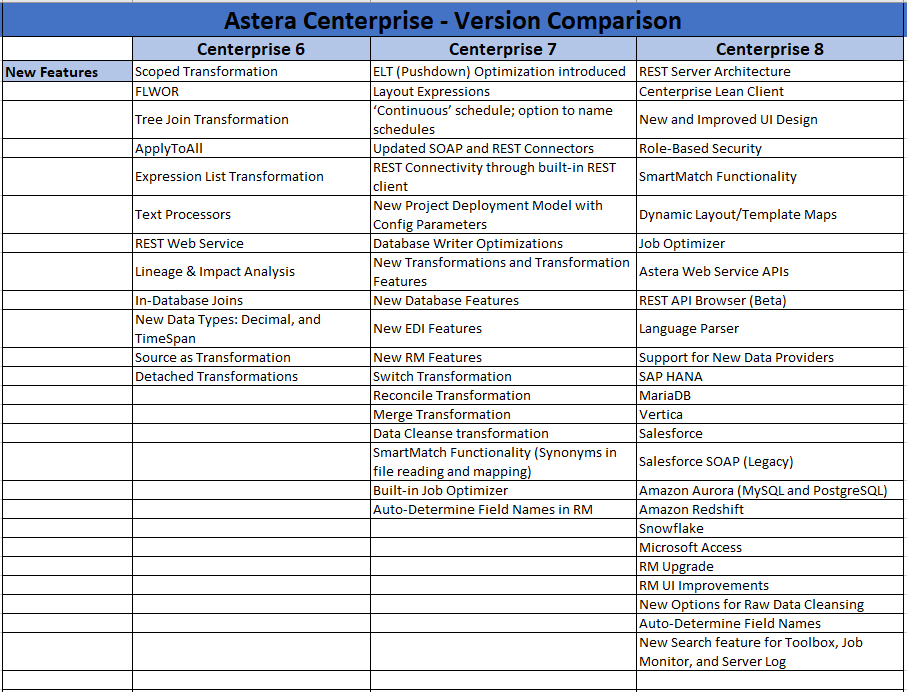
Astera Centerprise 7 - New Features¶
ELT (Pushdown) Optimization introduced¶
The support for ELT mode (stands for extract, load, transform), also known as ‘pushdown’ has been enabled in Centerprise 7. This mode allows certain flows to run directly on the database server, reducing or even eliminating the need for data to travel to and from Centerprise server. This brings in some tremendous performance gains for certain scenarios. In addition, the new Pushdown Verification feature allows the user to quickly check if the flow is eligible for pushdown.
Layout Expressions¶
Many objects on the flow allow expressions to be defined in field layout. This saves the need to have a separate Expression transformation object on the diagram, simplifying flow design.
‘Continuous’ schedule; option to name schedules¶
A new ‘Continuous’ option of schedule has been added to ‘Schedule Type’ options. This schedule type allows the user to create schedules that run in a continuous loop and specify custom delay settings. Moreover, you now optionally name the schedules you create in Centerprise 7.
Updated SOAP and REST Connectors; REST connectivity through built-in REST client¶
SOAP destination and SOAP lookups have been deprecated. Their functionality is offered by the single SOAP transformation object, which improves ease-of-use. REST connectivity is achieved thanks to the built-in REST client object.
New Project Deployment Model with Config Parameters¶
Centerprise 7 introduces a new way the flows can be deployed to the target environment, which streamlines the management of environment-specific database connections, network paths and flow variables. A project can be packaged into a single deployment file (aka CAR file), and the deployment file can have several config files with environment specific settings, making it possible to reuse the same deployment file and customize it for each target environment.
Database Writer Optimizations¶
Database write speeds are faster now for most database providers. The speed gain is especially noticeable for larger data sets using bulk or array insert. This performance improvement applies to several key database providers, including MSSQL, DB2, Oracle, Salesforce, MySQL, and Postgres.
Database writer framework has been redesigned to use temp tables with indexes on key columns, as well as temp files where applicable, which reduces network and database overhead, and increases bulk write speed.
New implementation of bulk UPSERT (Update followed by Insert) has been enabled for most database providers. This brings a significant speed advantage over previous versions, which processed data loads on a per record basis. Array Insert is faster than previous versions and it also optimizes memory use for typical batch sizes
New Transformations Features¶
A new *Transform Layout* interface has been added, which greatly simplifies the design and management of collections in complex object trees. This new feature is invoked via a command on the context menu for EDI Parser and EDI Builder objects, as well as the PassThru transformation. Using this new feature, the user can select a node and transform it to modify the structure of the object tree without the need to update the underlying schema.
New Database Features¶
*Identity Columns* and *Sequence Objects* are supported in more database providers now. Centerprise 7 introduces support of identity columns in Oracle destinations (this requires Oracle 12c or later) as well as adds more robust handling of sequence objects in the database providers that support it, including Oracle, DB2 and PostgreSQL. The handling of binary data in DB2 and Oracle has been improved. PostgreSQL destination has a new mode for bulk loading data from a temp file directly into the Postgres server. This increases write speeds for certain configurations.
New EDI Features¶
- Improved X12, HL7 and Edifact support
- EDI repositories for X12, HL7 and Edifact are no longer bundled with the client/server installer. They can be installed as needed by selecting the required dialect in the special Addon installer.
- EDI transaction configuration has been simplified. In 7.4, EDI versions and transaction sets can be selected directly in the EDI object on the diagram, rather than via the Trade Partner Profile dialog.
New RM Features¶
*Improved portability of Report Models across different locales*. Report Models can now be re-used in different locales without worrying about date/currency/number format compatibility in the target locale. The user can specify that the report model keeps the settings of the locale in which the model was created. These settings will apply regardless of the target environment/locale where the report model is used. Conversely, the report model can be set to adapt to the target locale so that the locale-specific settings are processed according to the target environment.
Other New Features¶
- *Importing Schedules and Deployments* – schedules and deployments can now be exported into a file, and then imported into a target repository. This simplifies repository migration tasks as it saves the need to backup/restore Centerprise repository.
- *FileSystem* object has a new property to return an extra record for each folder
- *EmailSource* object supports POP3 protocol now, in addition to IMAP. Email logging has been improved.
- *Write To* command on the context menu lets you add a destination object of your choice and map it in one step.
Switch Transformation¶
Switch transformation has been added to Centerprise’s library of built-in transformations. It matches source data for the criteria specified by the user, and wherever the criteria is met, it replaces the information in the particular field with the desired output (also specified in the layout). This gives users more control over their data and helps them manage it in a better way.
Reconcile Transformation¶
Reconcile transformation in Astera Centerprise enables the user to identify and reconcile new, updated, or deleted information entries within the existing data source. It can be applied in a wide variety of business scenarios that require a user to identify changes in multiple data records and capture them efficiently to drive critical business decisions.
Merge Transformation¶
Merges data from disparate sources for a consolidated and unified view. Merge transformation in Centerprise is designed to merge data fragments from disparate sources, based on some predefined logic, and present it in a consolidated form to draw actionable insights.
Data Cleanse transformation¶
A new transformation Data Cleanse Transformation has replaced the ApplyToAll transformation in Centerprise 7. It enables users to cleanse and prepare raw data for further usage. You can perform all sorts of data cleansing tasks such as removing whitespaces, unnecessary letters and digits, or any other specified characters. You can even perform a find-and-replace action on your data set or change strings to lower/uppercase as needed.
Flows that use ApplyToAll transformation, created on earlier versions of Centerprise will continue to work as is, and do not need any modifications after the upgrade.
SmartMatch Functionality¶
It is common to run into cases where you are dealing with alternate headers. For instance, a Product ID field can be defined in multiple ways in the incoming data sets. It can be called ProductID, Productid, Prod_ID or any other variation of it.
You can now create a Synonym Dictionary File in a project to store these alternate header values and Astera Centerprise will match these variations at run-time to map the incoming data. You can also do synonym-based mapping of the fields that have different names in the two objects by defining them in the dictionary and then using the Shift key while adding the maps.
Built-in Job Optimizer¶
Centerprise 7 introduces Job Optimizer that is designed to optimize and modify the flow at run-time. The Job Optimizer helps improve dataflow performance, reduce running times and optimize CPU, RAM, disk and network utilization. For example, it can remove unnecessary sort operations from the dataflow when the data has previously been sorted, which can dramatically improve flow running time. Conversely, Job Optimizer can add ORDER BY clause on database sources where needed so that the sorting takes place in the database as opposed to on the ETL server.
In addition, it also provides suggestions in the job trace to help the user further optimize the flow. An example below shows how Job Optimizer presents optimization improvements and suggestions in the job trace.
Auto-Determine Field Names¶
This new feature automatically detects the header name for each column of the data region from the source file loaded into a report model. To work with it, select the desired field, right-click on it and Auto Determine Field Names.
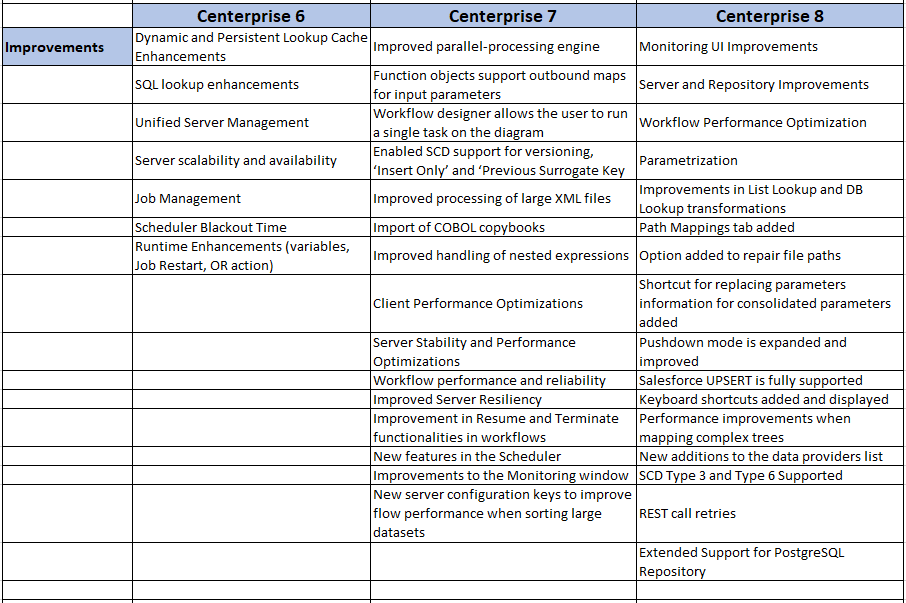
Centerprise 7 - Improvements¶
Improved parallel-processing engine that takes full advantage of multicore and multiprocessor hardware¶
Improved parallel-processing engine that takes full advantage of multicore and multiprocessor hardware. Cluster failover is now more robust compared to version 6. Overall better scalability to efficiently accommodate massive data volumes. Better handling of database connections and file streams. Better memory management when loading large data volumes during preview. Memory leaks have been fixed.
Function objects support outbound maps for input parameters¶
Function objects support outbound maps for input parameters, making it easier to connect them to other objects on the flow diagram. Functions also support optional parameters starting with version 7.1. Certain function objects also support collections.
Workflow designer allows the user to run a single task on the diagram¶
Workflow designer allows the user to run a single task on the diagram, skip certain tasks, run the flow up to the selected task, and start the flow from the chosen task.
Enabled SCD support for versioning, ‘Insert Only’ and ‘Previous Surrogate Key fields¶
SCD (Slowly Changing Dimensions) and Diff Processor components have been completely redesigned to address some functionality shortcomings from prior versions. SCD supports versioning, ‘Insert Only’ and ‘Previous Surrogate Key’ fields now. The new default mode for SCD is ‘No Output’, which means it is not showing outbound maps. This makes SCD and Diff Processor act more like database destination objects, which improves performance at run-time, and simplifies dataflow development.
Updated REST and SOAP connectors¶
Updated SOAP and REST connectors. SOAP destination and SOAP lookups have been deprecated. Their functionality is offered by the single SOAP transformation object, which improves ease-of-use. REST connectivity is achieved thanks to the built-in REST client object.
Improved processing of large XML files¶
Better handling of large XML files, both during preview and at run-time. This results in less chance of an out-of-memory situation when processing large files with limited RAM.
Import of COBOL copybooks¶
Report models can now extract data in a much more meaningful way from COBOL copybooks using the new visual hierarchical model building and modification capability. In addition, there is now a command in the report tree to import a copybook, which automatically creates data regions for each of the copybook objects and builds report model fields based on the copybook fields. Then users can rearrange the data regions in a way that forms a proper hierarchical model.
Improved handling of nested expressions¶
Ability to better handle nested expressions, which results in faster initialization and running times when using large expressions with lots of nested levels.
Client Performance Optimization¶
- Object trees refresh faster on the flow diagram
- Scrolling of objects with complex trees is faster
- Project load and refresh times are significantly faster for larger projects. In addition, lineage building can be temporarily disabled in Project Explorer, which helps optimize project tree response times
Server Stability and Performance Optimizations¶
- Flow termination logic has been improved. Flows terminate faster now, and the Server is generally more stable after terminating flows, even ones that involve termination of child processes and/or database transaction rollback
- Server framework has been updated to reduce the possibility for resource leaks, deadlocks and orphan connections, which further improves server stability
- Job Monitoring UI is much faster now
Improved Server Resiliency¶
We have greatly improved the server resiliency in Centerprise 7. This will ensure trouble-free server operations, better and quick recovery in the case of a database outage event, and overall improvement in the performance.
The server will no longer go in a permanent state of error in case of a database outage event and will automatically recover as soon as the connection is restored. Server connection will be automatically established when the connection to the repository database is available and no manual restarts will be required. Activity and error tracking are greatly improved in v7. The server writes database connection issues in the Windows event log and includes a link to the error file for easier troubleshooting.
Workflow performance and reliability¶
We have made some key improvements to the Astera server code to enhance the reliability and performance of workflows. Additional safeguards have been added to the workflow logic to make sure that workflows never get stuck in Running state even in the case of transient communication errors between the cluster servers and the repository database. Workflow completion times have also improved significantly as a result of these changes.
Improvement in Resume and Terminate functionalities in workflows¶
In the case of nested workflows and processes, if a child process (dataflow or workflow) returns an error and is not executed completely, the parent flow will automatically get terminated. Similarly, if a child flow is resumed then the parent flow will also be resumed automatically. Moreover, you now have the option to either resume your selected workflow from where it was terminated or rerun the entire flow from the beginning.
New features in the Scheduler¶
A new option is added to the Scheduler which lets you skip a new instance of a job if the previous instance is still queued or running. This prevents multiple instances of the same job from queuing in the case of a busy server.
Continuous schedule code has been revised with the goal of improving the reliability and performance of Continuous schedules, especially when running a busy server with multiple schedule types present. A minimum delay of 5 seconds is now required between continuous schedule runs. This is done to make sure the continuous schedule doesn’t get in the way of other schedules competing for the server resources.
Improvements to the Monitoring window¶
In Centerprise 7, we have significantly improved the UI response times when displaying and navigating long traces. This in turns help optimize the flow performance of the flows generating large trace output due to reduced database contention when reading and writing to the trace tables. In addition, the Monitoring window has a new Refresh button on the monitoring toolbar, which shows a snapshot of the current job status when the trace is paused.
New server configuration keys to improve flow performance when sorting large datasets¶
Centerprise 7 has a new Sort algorithm that is designed to optimize RAM and CPU use when performing sort operations on large datasets. This new model can bring about significant performance gains in certain scenarios. In addition, the server administrator is able to further optimize sort performance by modifying the additional configuration keys for Sort in ServerAdminConfig.xml file. Changing these settings can improve the performance of sorting operations by allowing the server to allocate more RAM if needed. Changing these values is recommended only if adequate RAM is available to the server during flow run-time.
Centerprise 8 - New Features¶
REST Server Architecture and Lean Client¶
Featuring an innovative implementation of the client-server architecture, Astera Centerprise 8 uses a REST-enabled server and lightweight, lean client application. The major part of processing and querying is handled by the server component, which communicates with the client using HTTPS commands. Therefore, database drivers are installed only on the Centerprise server. This enables you to scale horizontally and add multiple clients to an existing cluster of servers without the need to replicate driver installation on every machine.
With this functionality, we aim to minimize the logistical and maintenance challenges involved in installing Astera Centerprise, creating a more scalable architecture and simplifying software deployment.
New and Improved UI Design¶
We’ve updated the look and feel of the product with new icons, modern design, and eye-catching colors. The drag-and-drop development environment has been revamped into an improved and more responsive UI to deliver a more user-friendly experience. In addition to the enhanced visual appeal, this new UI is designed to simplify navigation and enable easier implementation of integration tasks.
Role-Based Security¶
The new Centerprise 8.0 includes authorization and authentication features to secure any action performed by authenticated users against the run-time and design-time components of the solution. The security is built around three key areas:
- *User authentication* via bearer-token authentication
- *Secure domain communication* between the client and server over TCP/IP and HTTP protocols
- ***Role-based access control ***via an intuitive user management and access control dashboard
These enhancements will help administrators prevent unauthorized access to data management workflows and ensure access policies for both internal and remote users.
SmartMatch Functionality¶
We have introduced the SmartMatch functionality in Centerprise 8 to simplify complex mapping jobs in ETL flows. It uses a Synonym Dictionary File created by the user to resolve mapping issues that arise due to naming inconsistencies in the incoming source data. The Synonym Dictionary file is a simple txt file in which users can specify variations of the header name in a pipe delimited format and Astera integration server will automatically read and match field names at run-time based on the predefined information in the dictionary.
Job Optimizer¶
The Job Optimizer enables users to optimize ETL performance and minimize job execution time. It issues recommendations to optimize integration flows, at runtime in job trace. These recommendations can be removing repetitive sort operations on presorted data, apply an ORDER BY clause on database sources to run sort operations in the database, or any other suggestion to optimize your flow. As a result, it helps bring a significant increase in performance by efficiently managing the RAM, CPU, network and disk utilization while executing jobs.
Astera Web Service APIs¶
We have published an extensive library of Astera REST web service APIs. Now, you can perform a wide range of data integration functions by using APIs to directly communicate with the Centerprise server and get the required data. Here are the resources that are available for the users in the first round of the beta release:
- Account APIs: Resources related to account login and user authentication.
- Server APIs: Resources related to job monitoring, schedules, and server information.
REST API Browser (Beta)¶
Astera Centerprise 8 features an intuitive REST API Browser that enables connectivity to popular business applications via single-step authentication to make HTTP calls. It decouples data from the point of origin to make it consumable, independent from the source system.
To use an API, the user needs to perform a one-time set up for the API connection in the Import API screen. Then, the REST API Browser populates all the HTTP requests (GET, PUT, POST, DELETE, PATCH) present in that specific API. Users can access and integrate these calls in their dataflows simply by dragging-and-dropping the object from the Browser.
Language Parser¶
We have added the language parser functionality to the Expression Builder to enable advanced expressions such as interpolated string and verbatim. This will enable users to compile different values from incoming datasets into an expression and present it as an interpolated string in the output.
Support for New Data Providers¶
Delivering on the popular demands from our customers, we have pushed the envelope to offer native connectivity to several new databases, data warehouses, and enterprise applications.
RM Upgrade¶
Astera ReportMiner upgrade is shipped with a complete UI overhaul and a number of bug fixes and improvements to the existing features. The UI has been redesigned to present a fresh, new look while also simplifying navigation and improving user experience. Here’s a summary of the improvements in Astera ReportMiner upgrade:
UI Improvements¶
New Options for Raw Data Cleansing¶
Auto-Determine Field Names¶
Compared to previous versions, we have now introduced dedicated properties panel for Report Options, and Region, Pattern and Field Properties in ReportMiner. Each of these panels has a dedicated toolbar with relevant shortcut icons, making it convenient for users to specify and configure properties of the various components of a Report Model such as data regions and fields, from within a single panel. The main toolbar too now features shortcuts to facilitate users in creating report models.
We have added a couple of new options to the ‘Remove’ options used for cleansing and scrubbing the extracted data in ReportMiner. In addition to removing extra spaces inside the text, text qualifiers (surrounding quotes), and leading and trailing spaces, you can now remove all white spaces and punctuations from within the extracted data by simply checking the ‘All White Spaces’ and ‘Punctuations’ options under the ‘Remove’ section in the Field Properties panel.
While creating extraction templates for reports, you can now automatically determine field names using the ‘Auto Determine Field Name’ option. Once you’ve specified a data region, add data fields, right-click on a data field and select ‘Auto Determine Field Name’ from the context menu. This will automatically identify and update field names as they appear in a report.
Centerprise 8 - Improvements¶
Monitoring UI Improvements¶
Centerprise 8.0 includes advanced server monitoring and job management features to enable administrators to proactively manage job monitoring, prevent downtimes, and identify the causes of server failure. Moreover, in case of server failure or outage, users can generate a diagnostic file to get details about the state of the server and the machine where it’s deployed.
This diagnostic file contains information such as server status, server health, active connections, process memory size, thread count, installed drivers, etc. which you can use for troubleshooting and improvements. Furthermore, you can track, monitor and manage the jobs scheduled, running or executed on the server in the Job Monitor window.
Server and Repository Improvements¶
Job concurrency has been optimized. The server now counts only active running jobs (whether it’s a parent or child flow) against the maximum limit for concurrent jobs and will not include the idle parent jobs of those running jobs. For instance, if a parent workflow (A) constitutes another workflow (B) which calls a dataflow (C), the job run for dataflow (C) will be counted as a single job and could be run concurrently with other jobs (scheduled or running) on the server at that time. This improvement, however, is not enabled by default and will only be available for certain licenses.
Purge function for repository has been improved. Users can now set a frequency (in terms of days) to purge the repository of old and outdated records. You can also define a time window (in hours) for when you want to purge the repository as well as purge timeout settings, and purge chunk sizes, to help optimize purging performance in busy environments.
Workflow Performance Optimization¶
Another significant highlight of Centerprise 8.0 is the improvement in Astera server code to optimize the performance, reliability, and scalability of workflows. The workflow execution logic has been optimized to eliminate any chance of a workflow hanging amidst session in any state (queued, running, or terminating), even if there are transient communication errors between the main server or cluster servers and the repository.
Parametrization¶
The parametrization functionality in Centerprise 8.0 has been improved to support expression compilation in variables. The syntax has been changed from ‘$ ()’ notation to ‘{}’. However, this update won’t affect the parameters incorporated in existing flows. The current flows will continue to run seamlessly as before, without having to manually update the syntax. And once you save any flow that was using previous notation ‘$ ()’ in version 8, it will automatically get converted to ‘{}’.
Improvements in List Lookup and DB Lookup transformations¶
New options added to the layout builder screen of List lookup and DB lookup transformations. Now you can keep the source value for the values that do not match the replacing criteria in a list or a database table.
Path Mappings tab added¶
A new tab for specifying client and server path mappings has been added on the Cluster Settings This is particularly useful when the client and server reside on different networks or network file systems and their paths have to be mapped to correctly transfer files at run-time.
Option added to repair file paths¶
For better project management, we have added a new option to repair the file paths for files in any particular folder. This option is useful if you are working in a case-sensitive environment.
Shortcut for replacing parameters information for consolidated parameters added¶
Now you can replace the common parameter information for all objects in a flow with this command right from the dataflow screen.
Pushdown mode is expanded and improved¶
More transformations and expressions are now supported in the Pushdown mode. We have also improved the explanations for the verification errors for easier troubleshooting.
Salesforce UPSERT is fully supported¶
Salesforce UPSERT is now fully supported. UPSERT uses an external ID field in the Salesforce table to match incoming data with existing records.
Keyboard shortcuts added and displayed¶
Keyboard shortcuts are enabled for various task windows. You can view the shortcut keys next to their respective commands.
Performance improvements when mapping complex trees¶
Runtime performance of the dataflows containing complex tree structures is improved.
SCD Type 3 and Type 6 Supported¶
SCD type 3 and type 6 are now supported.
REST call retries¶
For the REST calls running in timeout error, Centerprise will automatically make up to three retry attempts to process the call.
Extended Support for PostgreSQL Repository¶
We have enabled support for PostgreSQL for creating cluster databases and server repository in Astera Centerprise 8.2. You can now use a PostgreSQL database to store and manage the record of the server’s activity, including job logs, job queues, and schedules.
Important Considerations and Known Issues¶
Digest Authentication¶
Digest Authentication is not supported in Centerprise 8.
VC++Prerequisite for Centerprise 8¶
VC++ is a prerequisite for Centerprise 8.3. Before migrating or updating to v8.3, users will need to install VC++ redistributable package on their machine. The bitness (32-bit or 64-bit) of Centerprise and VC++ redistributable package should be same. Minimum required version is Microsoft Visual C++ 2015-2019, v14.26. VC++ redistributable package can be downloaded from the following link:
Miscellaneous Updates and Important Considerations.¶
Read more on the other updates and important considerations related to Centerprise 8 on the link below:
Upgrading from Centerprise 6 to v7¶
Astera Centerprise 7 is shipped with new features and functionalities that require an update to the Cluster Database used by the integration server. Click on the link below to find information on how to upgrade the Cluster Database for use with Centerprise 7, while migrating from Centerprise 6.