Distinct Transformation¶
Overview¶
Distinct transformation in Astera Centerprise removes duplicate records from the incoming dataset. You can use all fields in the layout to identify duplicate records, or specify a subset of fields, also called key fields, whose combination of values will be used to filter out duplicates.
## Use CaseConsider the scenario where we have data coming in from an Excel source and the dataset contains duplicate records. We want to filter our all the duplicate records from our source data and create a new dataset with distinct records from our source data. We can do this by using the Distinct transformation in Astera Centerprise. To achieve that, we will specify data fields with duplicate records as Key Values.
In order to add a separate node for duplicate records inside the Distinct transformation object, we will check the option Add Duplicate Records. Then write both distinct and duplicate output into a Delimited File Destination.
Let’s see how to do that.
How to work with Distinct Transformation¶
1. Select the relevant source object from the Sources section in the toolbox. In this example, we have our source data stored in an Excel source. Therefore, an Excel source would be used.
(Read: How to work with an Excel source)
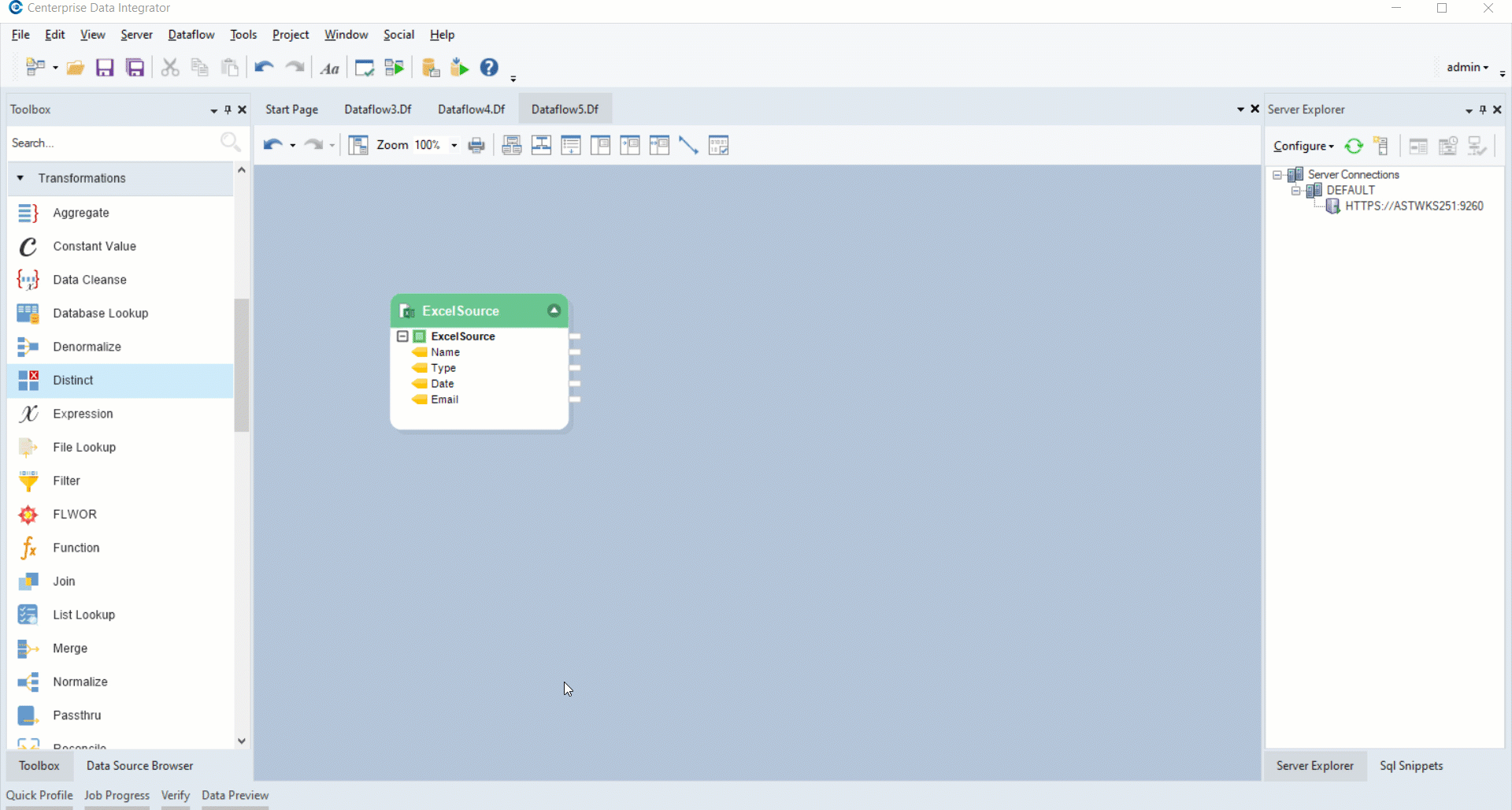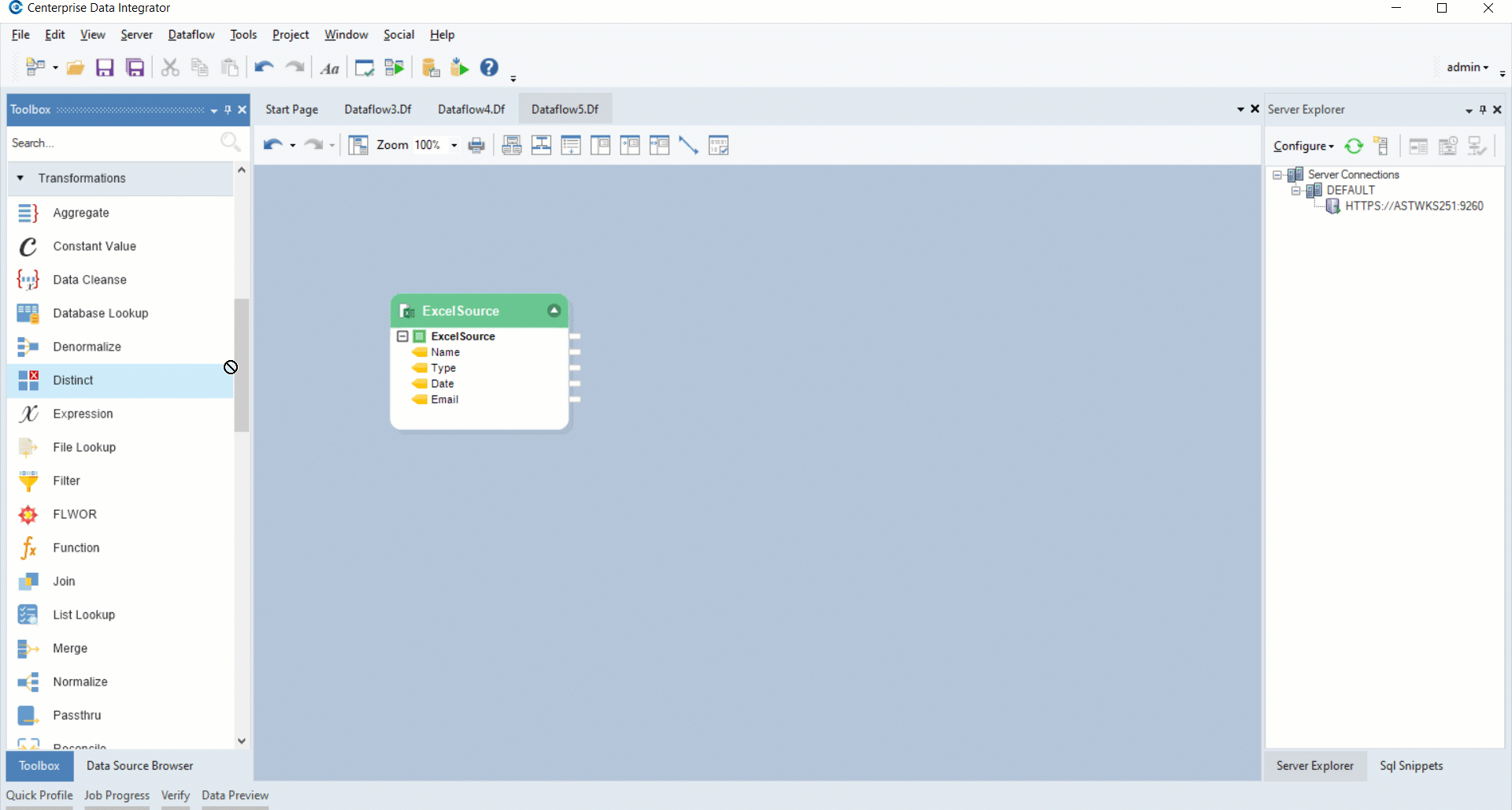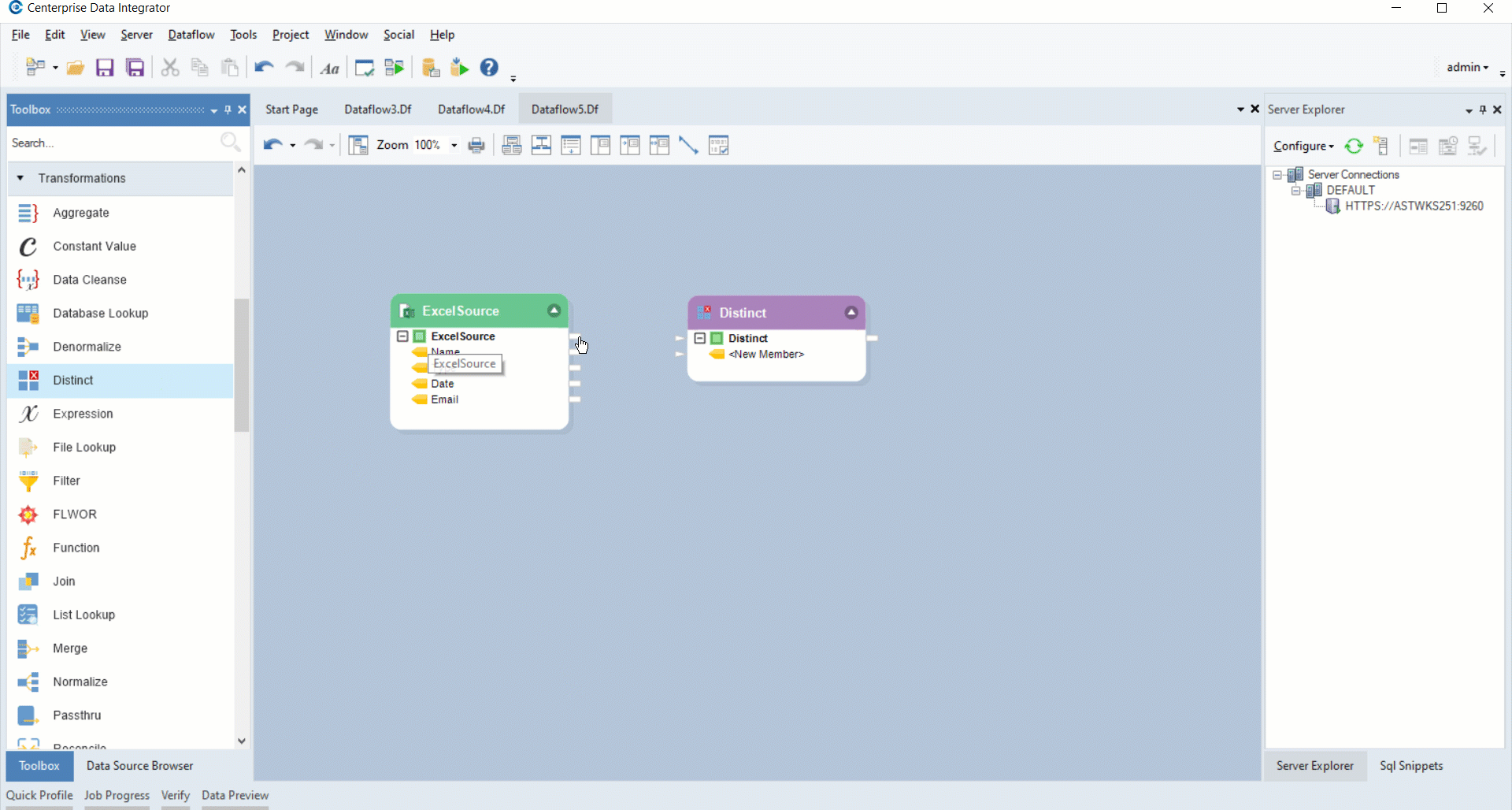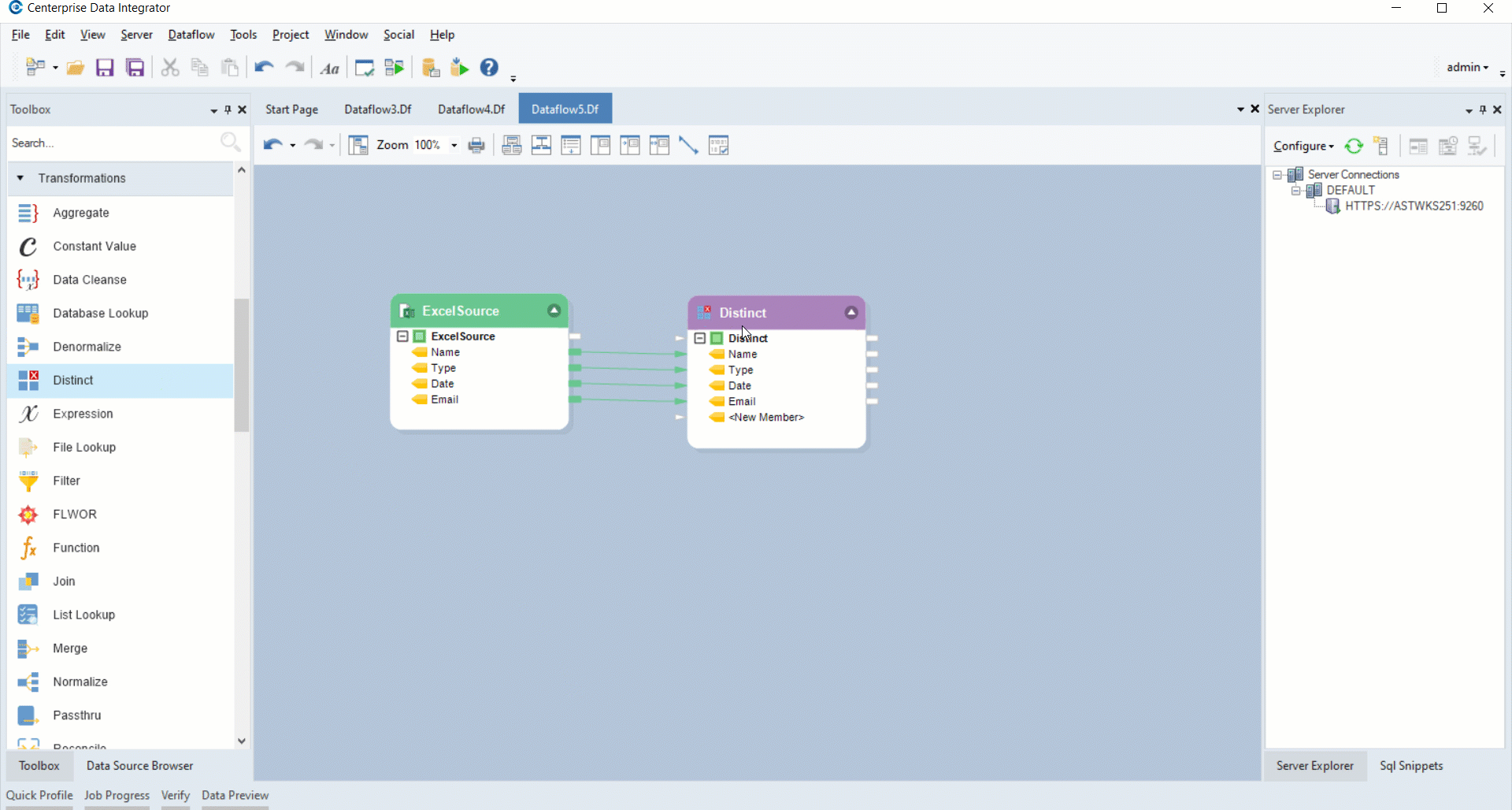
2. To apply Distinct transformation to your source data, drag and drop the Distinct transformation object from the Transformations section in the toolbox. Map the fields from source object by dragging the top node of ExcelSource and dropping it over the top node of Distinct transformation object. To do that, go to Toolbox>Transformations>Distinct.
3. Now, right-click on the Distinct transformation object and select Properties. This will open the Layout Builder screen where you can modify fields (add or remove fields) and the object layout.
Layout Builder screen will look like:
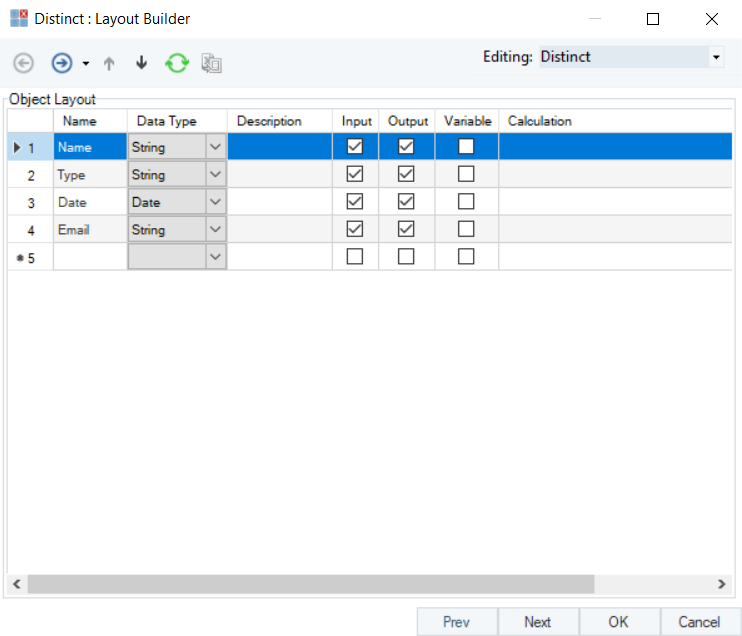
4. Click on Next. Distinct Transformation Properties screen will open.
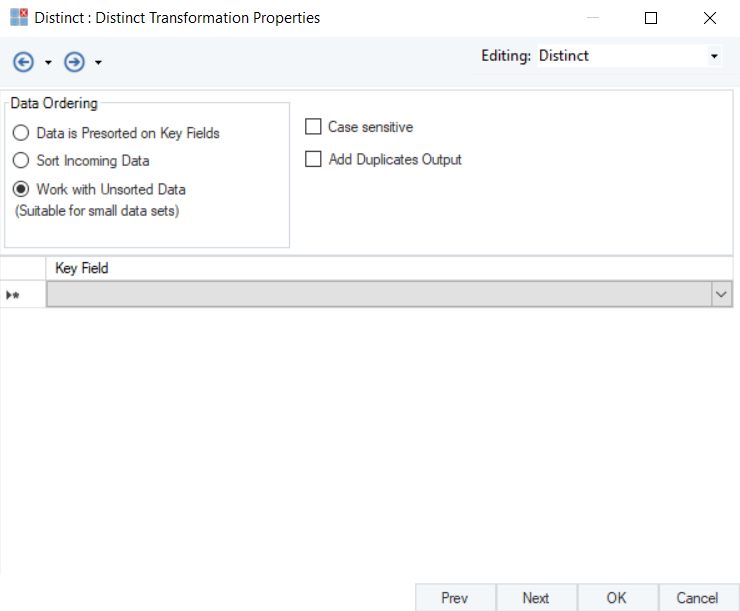
Data Ordering
- Data is Presorted on Key Fields: Select this option if the incoming data is already sorted based on defined key fields.
- Sort Incoming Data: Select this option if your source data is unsorted and you want to sort it.
- Work with Unsorted Data: When this option is selected, the Distinct transformation object will work with unsorted data.
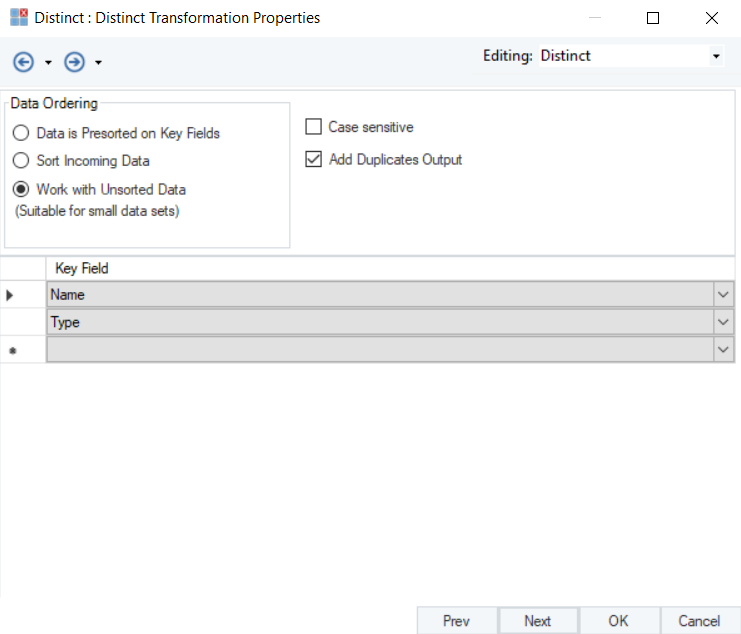
5. On this screen, the distinct function can be applied on the fields containing duplicate records by specifying them as Key Field.
(Note: In this case, we will specify Name and Type fields as Key Field)
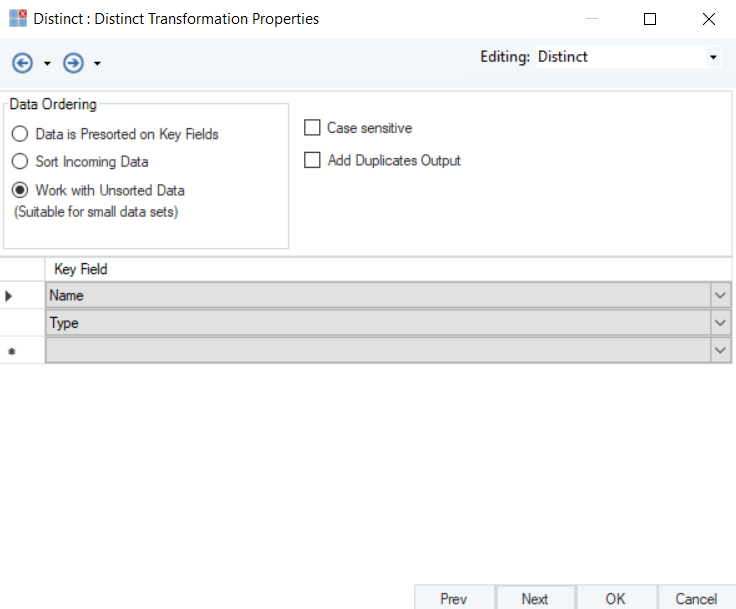
You can now write the Distinct output to a destination object. In this case, we will write our output into a Delimited destination object.
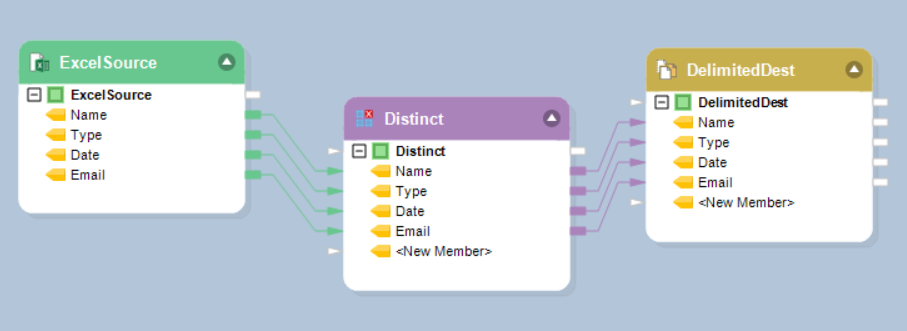
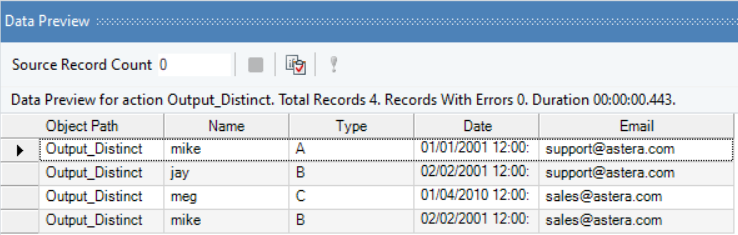
6. Right-click on Delimited Destination object and click Preview Output.
Your output will look like:
To add duplicate records¶
1. To add duplicate records in your dataset check the Add Duplicates Output option in the distinct . transformation properties.
2. When you check this option, three output nodes would be added in the Distinct transformation object.
- Input
- Output_Distinct
- Output_Duplicate
(Note: When you check Add Duplicate Records option, mapping from source object to the Distinct transformation object will be removed.)
3. Now, map the objects by dragging the top node of ExcelSource and dropping it over on the Input node of **Distinct ** transformation object.
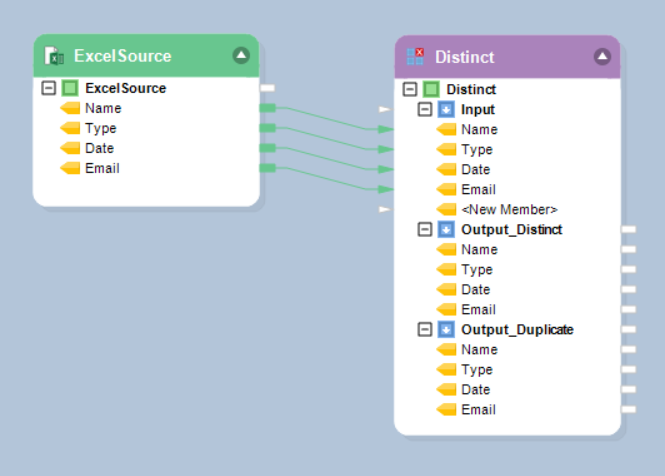
4. You can now write the Output_Distinct and Output_Duplicate nodes into two different destination objects to get the outputs accordingly. In this case, we will write our output into a Delimited destination object.
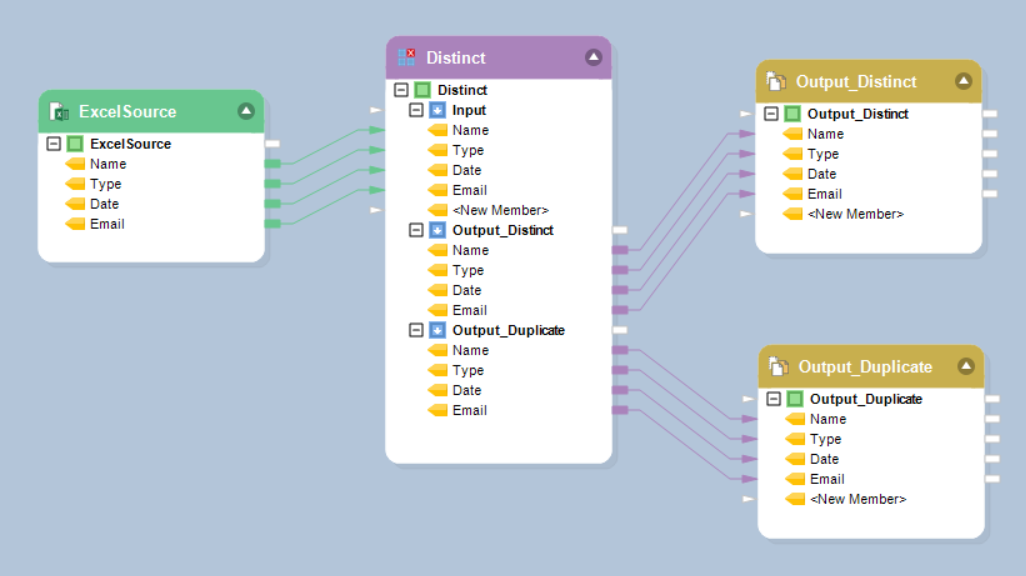
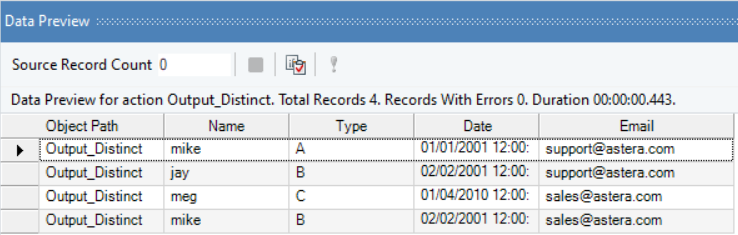
Distinct output:
Duplicate output:
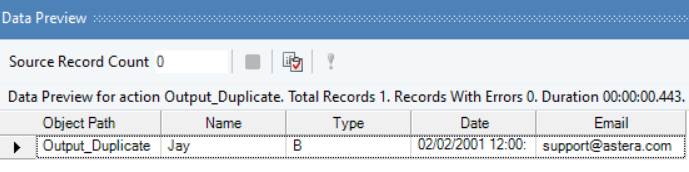
So, duplicate records have been successfully separated from your source data.