Connecting to Amazon Redshift Database¶
Amazon Redshift is one of the most popular, fully managed cloud data warehouse services. It allows users to work with large scale data workloads for analytics which can further help in compiling reports for various business functions. It is popular for data storage due to its scalability, speed, and efficient compression features which process bulk loads of data.
Astera Centerprise offers code-free connectivity to Amazon Redshift databases at both source and destination points. These databases can also be connected for use in other functionalities such as Database Lookup, SQL Query Lookup, and Database Write Strategies depending on the type of business decisions to be performed.
To learn more about Amazon Redshift Databases, click here.
In this article, we will cover:
1. A use case where Amazon Redshift Database is being used in Astera Centerprise
2. Connecting to an Amazon Redshift database in Centerprise
3. Different data loading and reading options for Amazon Redshift database objects in Centerprise
Use Case¶
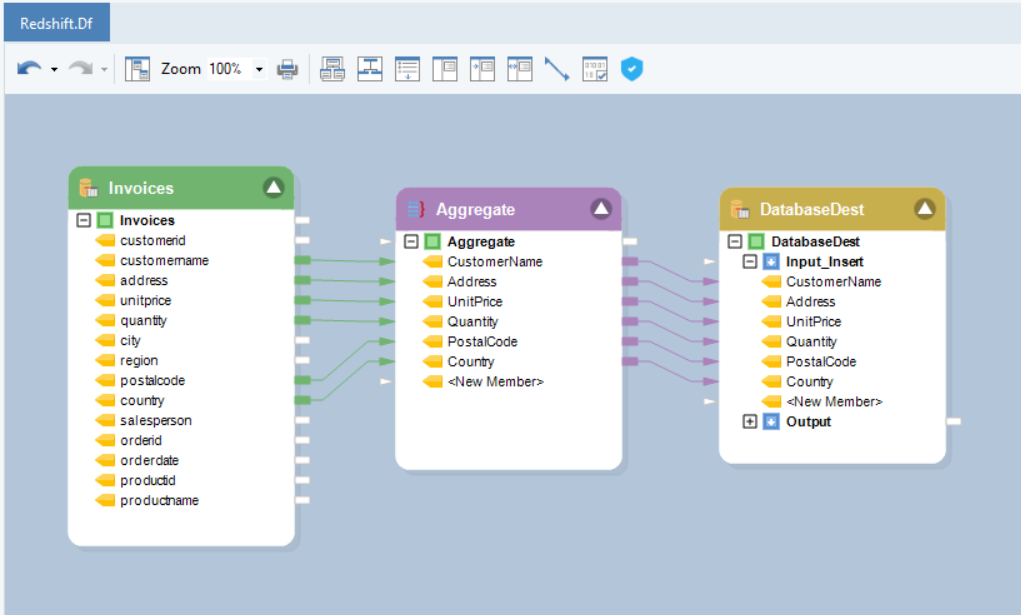
We have sample Invoice data stored in an Amazon Redshift database table. The data contains information about the orders placed by customers. We want to aggregate records of customer orders to find the sum of the price and the quantities ordered by each customer. We will then create a new table in the Amazon Redshift database and write this data to it.
We will be using the Database Table Source object to source data from the Amazon Redshift database.
1. To configure the Database Table Source object, right-click on its header and select Properties from the context menu.
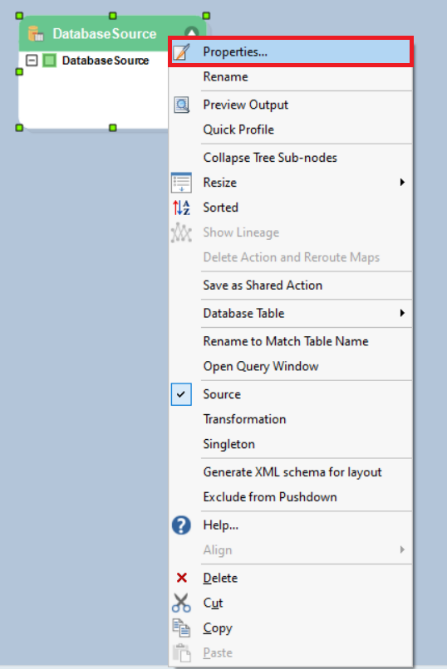
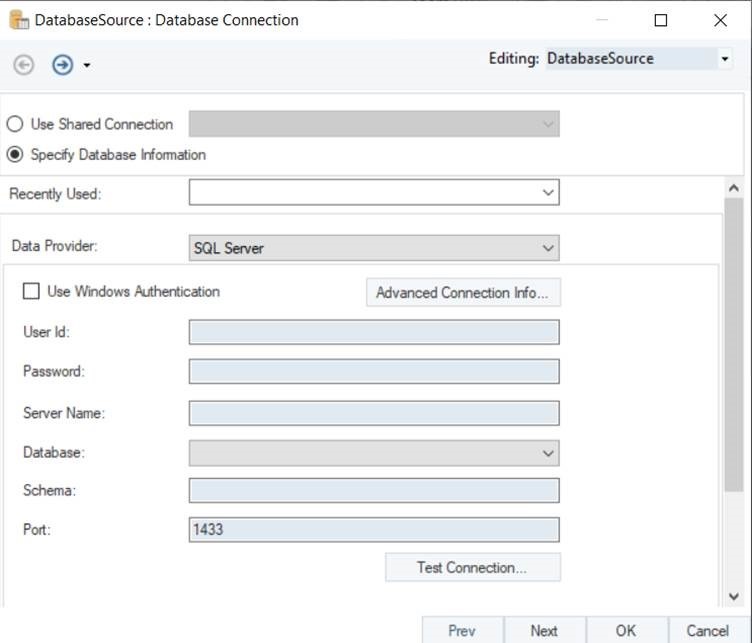
This will open a new window where you can configure a connection with the Amazon Redshift database.
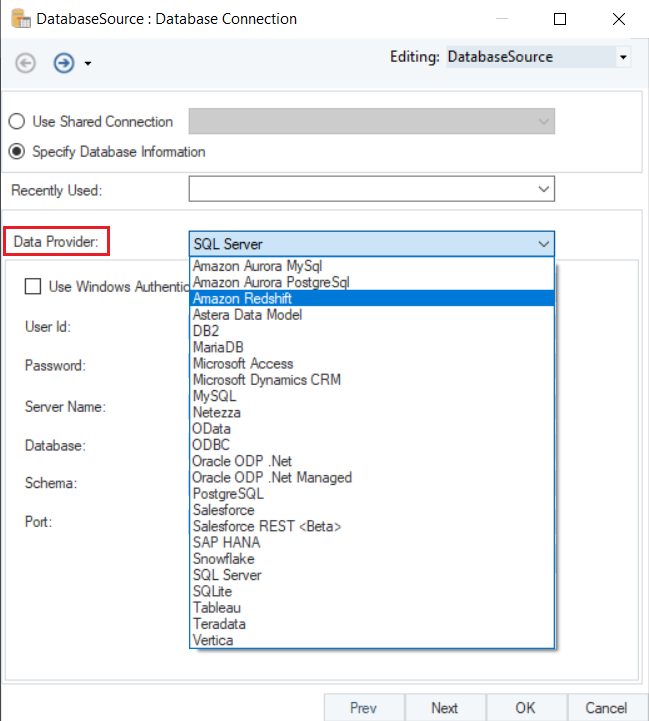
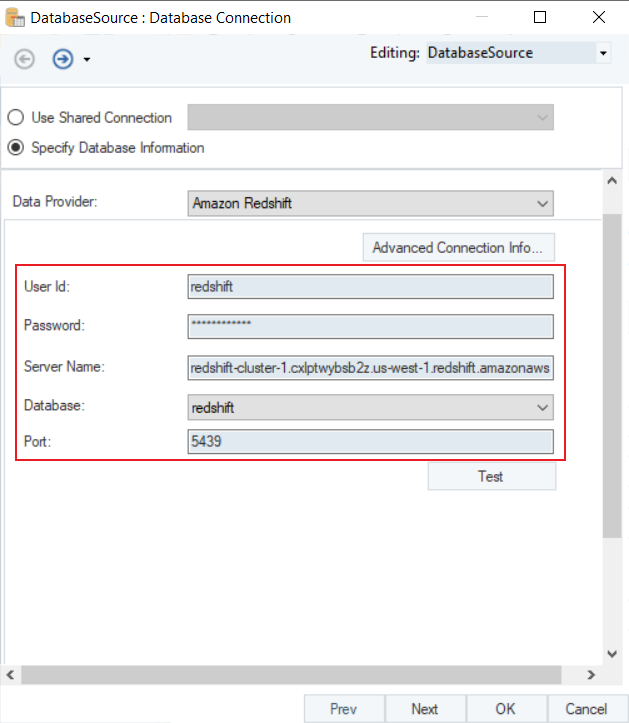
2. The first step is to select the Data Provider. Select Amazon Redshift as your data provider from the drop-down list.
- Enter the required credentials for your Amazon Redshift account.
- User ID
- Password
- Server Name
- Database
- Port
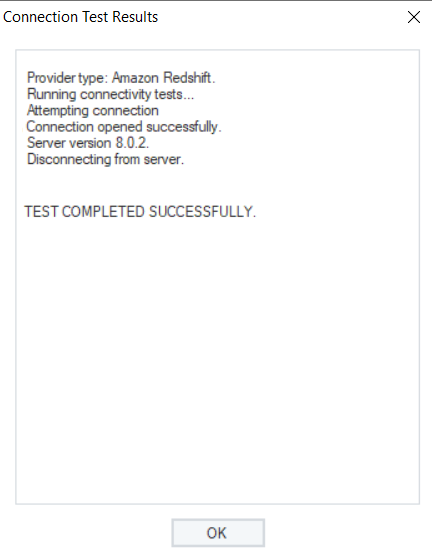
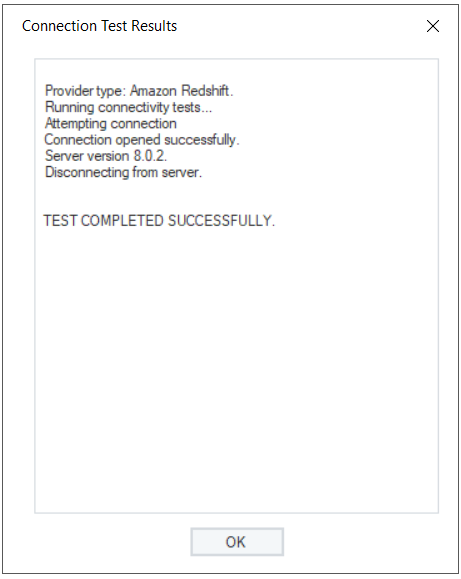
- Test Connection to make sure that your database connection is successful, and click Next to proceed to the next screen.
3. Here, you can Pick Source Table and modify Reading Options for your Amazon Redshift database.
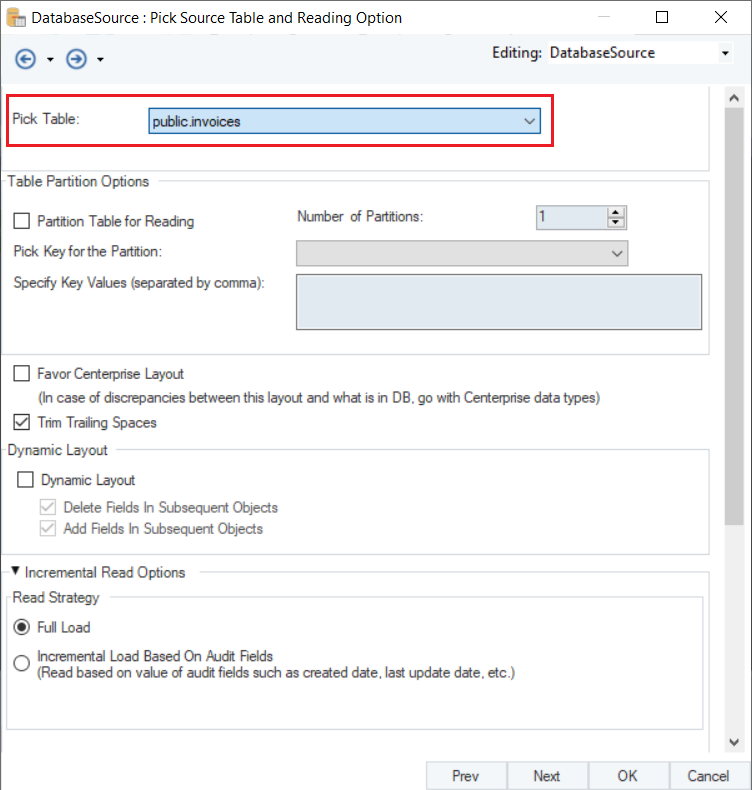
Note: In this case, we will select the Invoices table.
To learn more about data reading options in a database table source, click here.
4. Now, we will use the Aggregate transformation to group customer records and find the sum of unit price and quantities for each.
To know more about how the Aggregate transformation works in Astera Centerprise, click here.
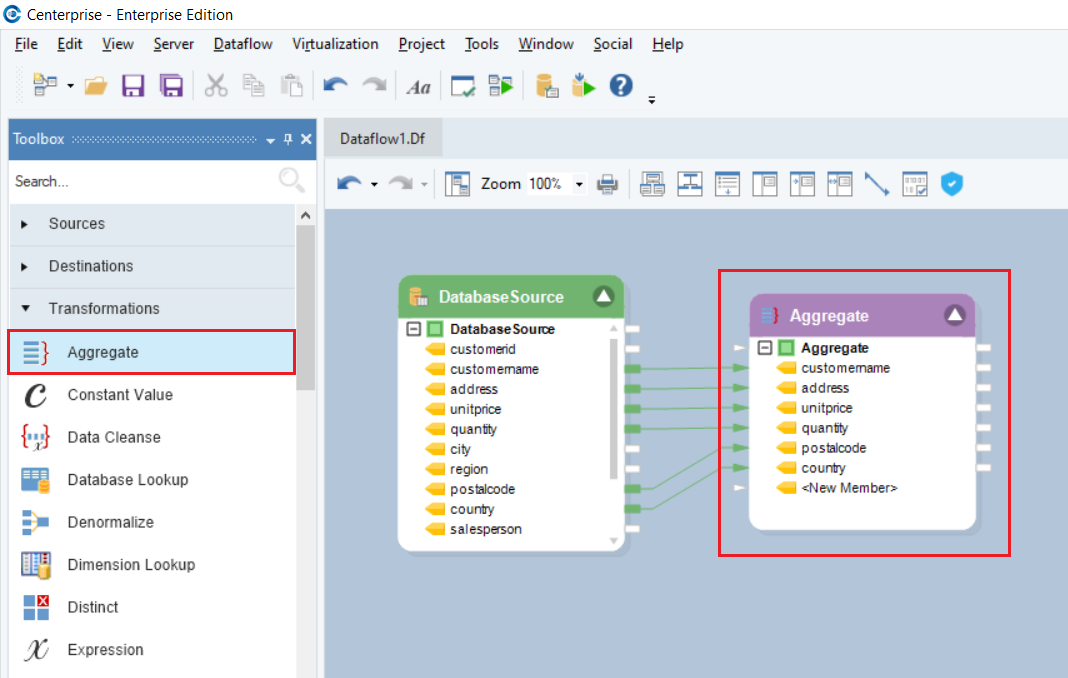
5. Next, we will create a new table in the Amazon Redshift database and write the transformed data to that table using the Database Table Destination in Astera Centerprise.
To configure the Database Table Destination object, right-click on its header and select Properties from the context menu.
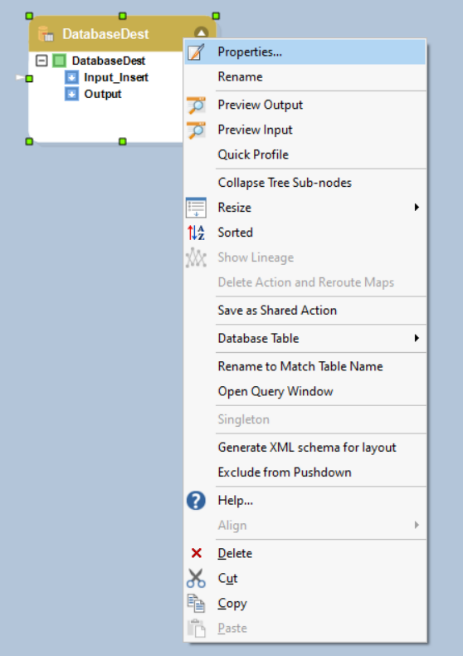
This will open a new window on your screen.
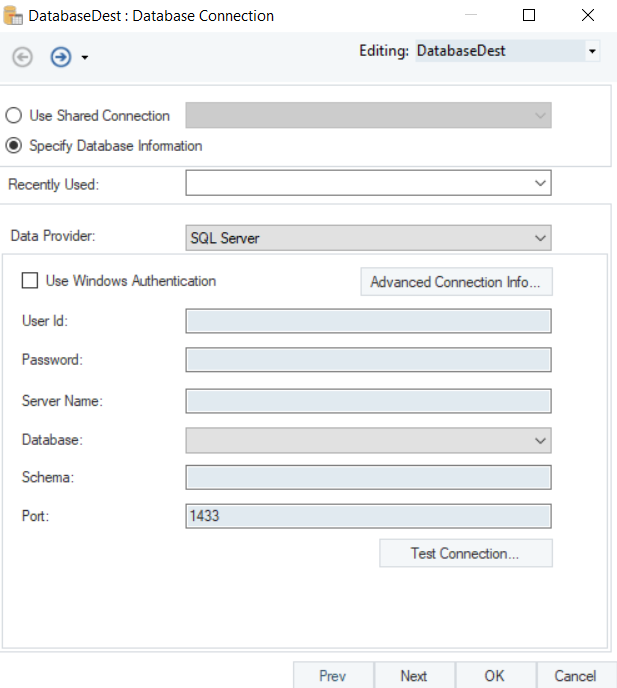
Here you can configure the properties for the Database Table Destination object.
The first step is to specify the Database Connection for the destination object. Select Amazon Redshift as your data provider from the drop-down list.
Alternatively, you can use the Recently Used drop-down and select Amazon Redshift connection from the list, since you have connected to it previously while configuring the source object.
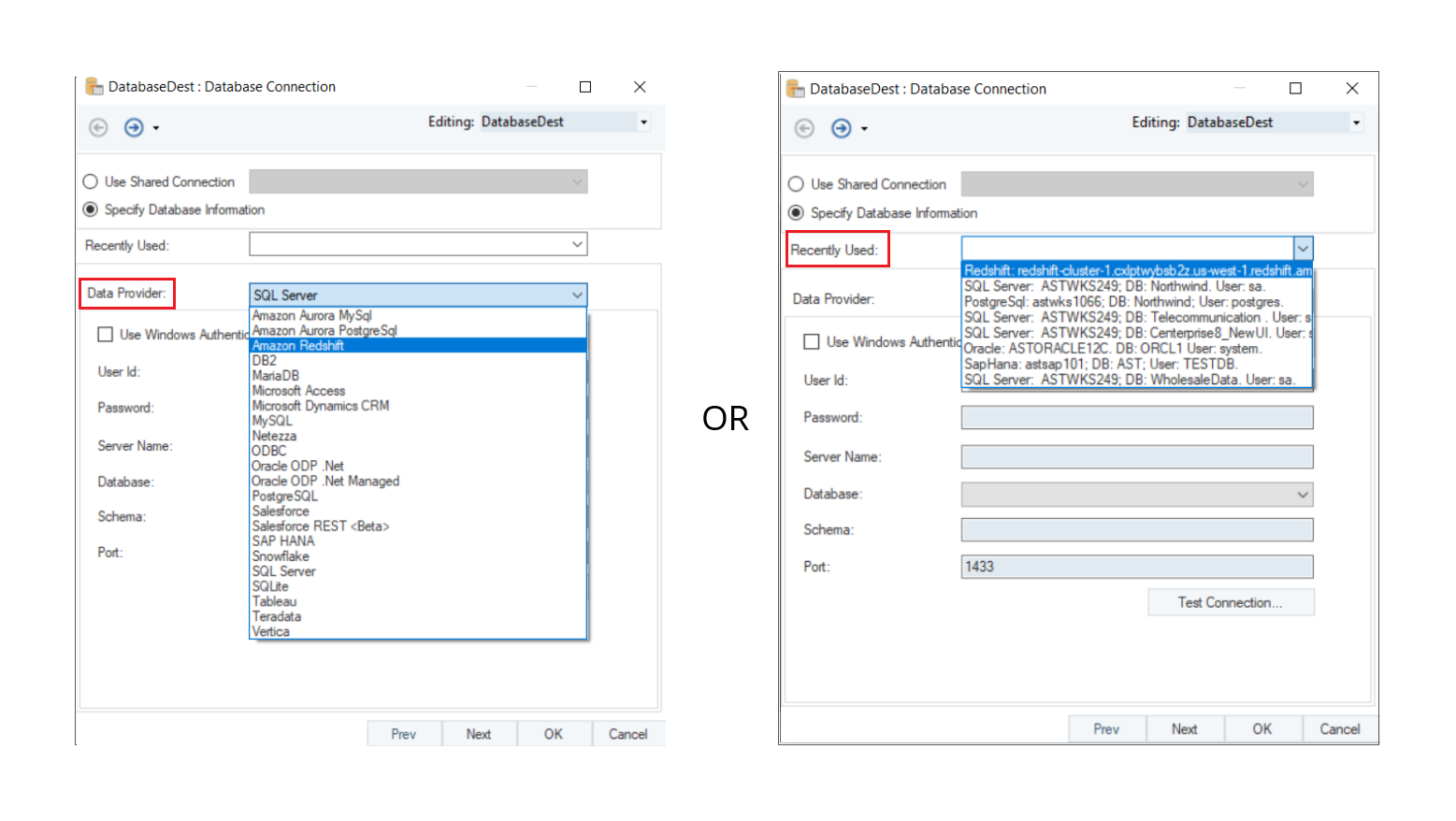
- Enter the required credentials for your Amazon Redshift data provider account.
- User ID
- Password
- Server Name
- Database
- Port
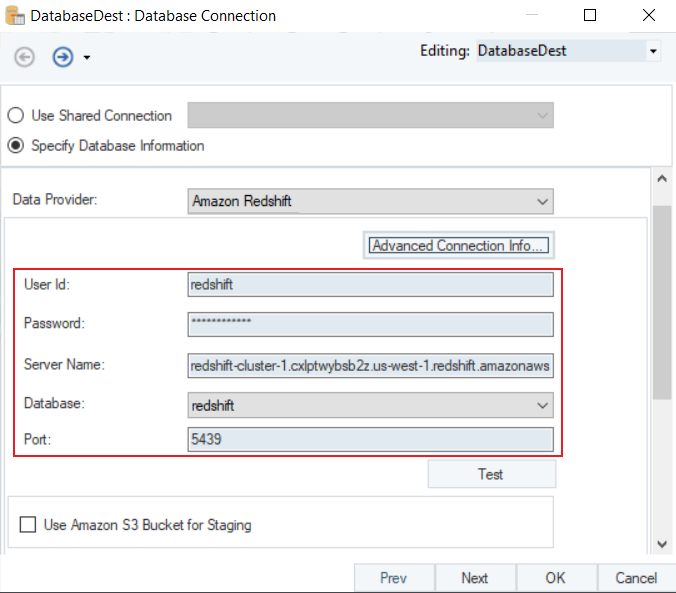
- Test Connection to make sure that your database connection is successful.
If you are using the Bulk Insert option for loading the data into the Amazon Redshift database, there is an option to provide S3 Bucket Credentials for Amazon Redshift.
The S3 Credentials require:
- S3 Key
- S3 Secret
- S3 Bucket
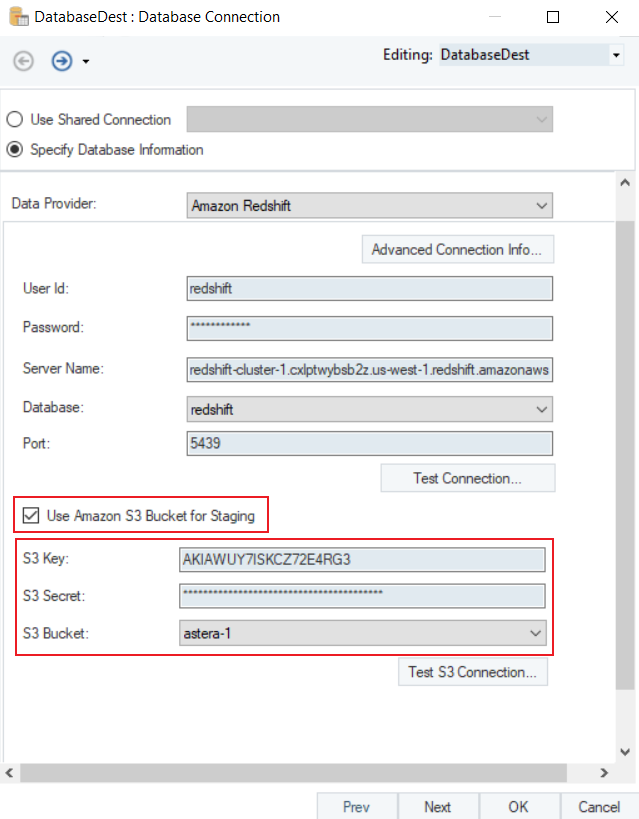
In this case, we will provide the credentials to the S3 Bucket since we will be loading the data through bulk insert with batch size.
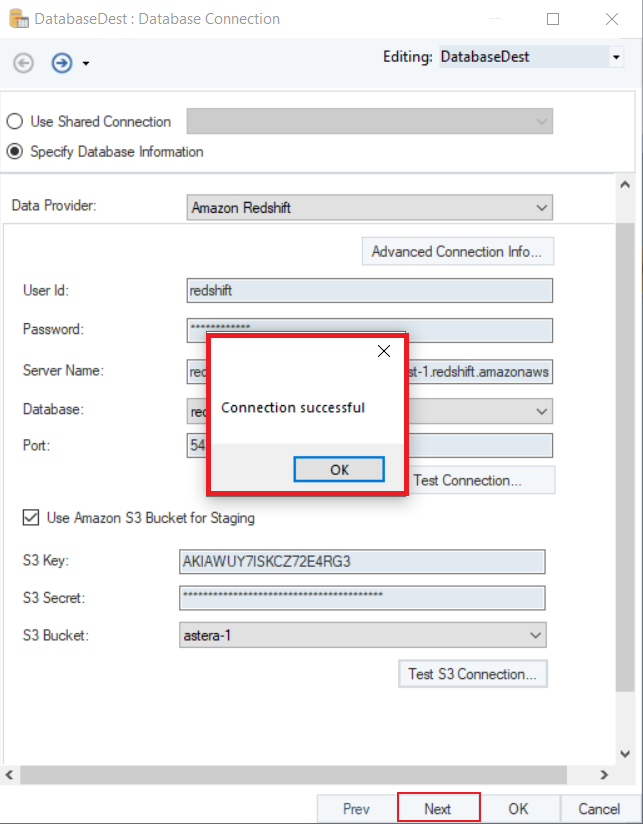
- Test S3 Connection to check if the bucket has been connected successfully. Click OK, and then Next to proceed to the next screen.
On the next screen, you can Pick Table or Create Table and modify Writing Options for Amazon Redshift Database on the Properties screen.
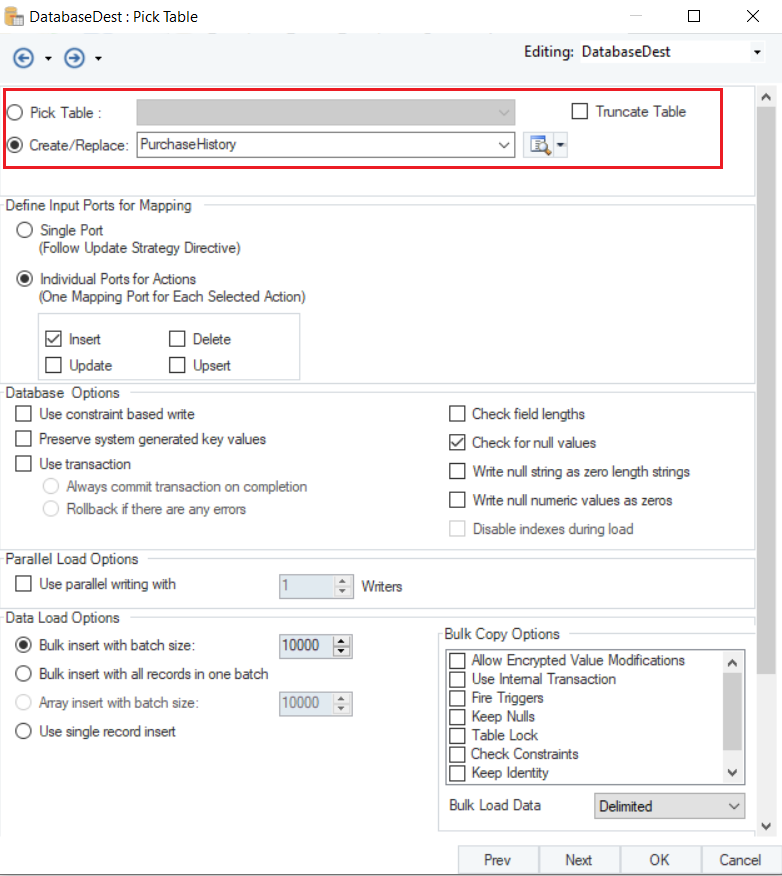
Note: In this case, we will create a new table and name it as PurchaseHistory.
To read more on the different data writing options available for a database table, click here.
There are different Data Load Options for Amazon Redshift data provider, we will select Bulk Insert with Batch Size since we have connected to the Amazon S3 Bucket and adjust the batch size to 1000.
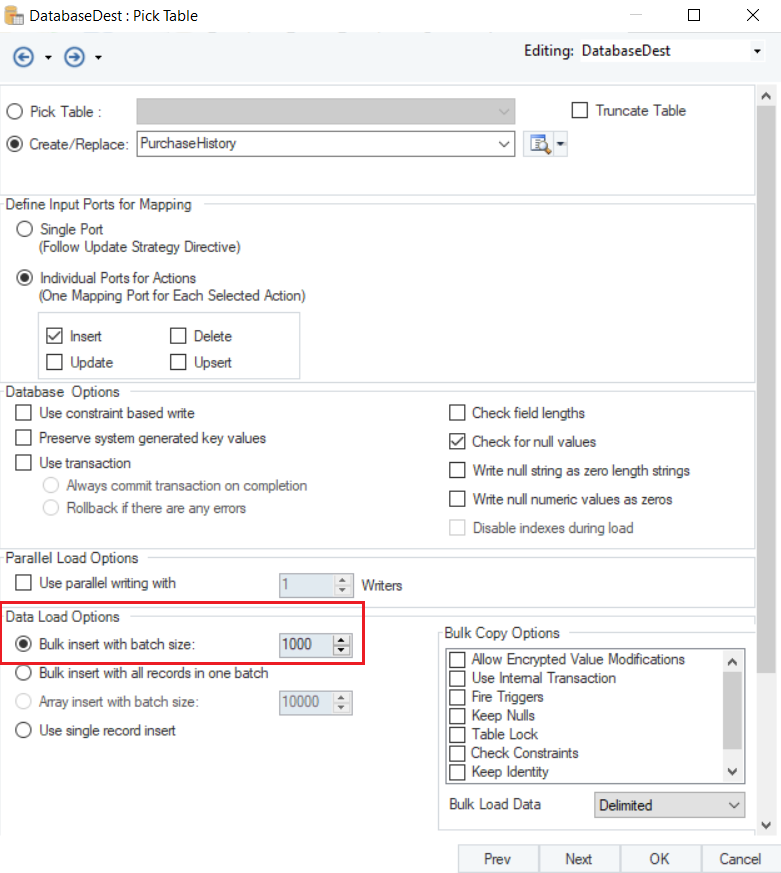
Once you have set the data reading options, click OK.
We have successfully configured Amazon Redshift as your database provider for the Database Table Destination object. The data will now be written to the Amazon Redshift Database once the dataflow is run.
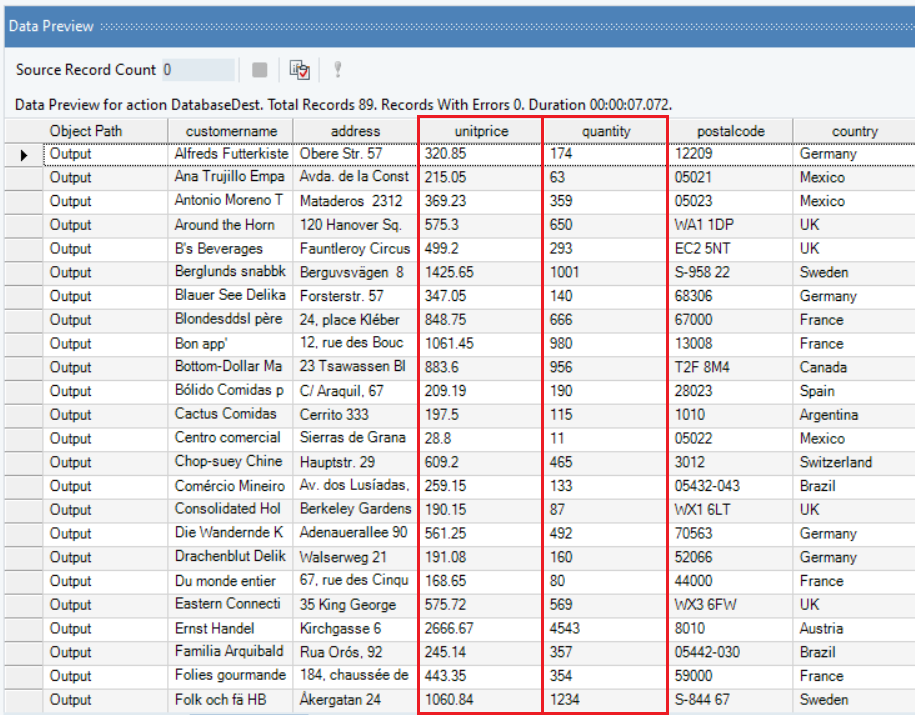
If we preview the output for the destination object, we can see that the summed up unit price and quantities for each customer record have been written into the destination table.
We have successfully connected to Amazon Redshift Database and completed our use case in Astera Centerprise.