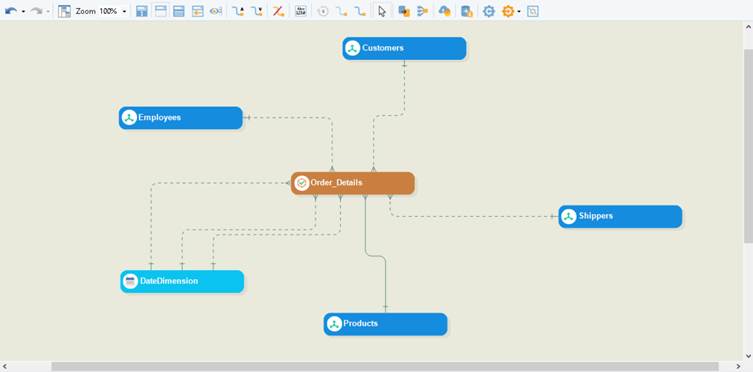
Introduction to Data Vaults¶
A Data Vault is a hub-and-spoke based data warehouse modeling technique developed by Dan Linstedt. Data Vault was designed to improve data warehousing scalability and flexibility with emphasis on agility in the process and improving the data’s auditability. Thus, enabling a complete audit trail of stored data and making it well suited for large and complex data sets.
There are three layers in a Data Vault: Raw Vault, Business Vault, and Information Vault (Presentation Layer).
The Raw Vault is a non-volatile layer that keeps data in an integrated, function oriented, historical, time variant, and original format where it is easily auditable and transparent. Hard Business rules are applied before loading data into the Raw Vault layer. The Raw Vault layer comprises of entities such as Hubs, Links, and Satellites.
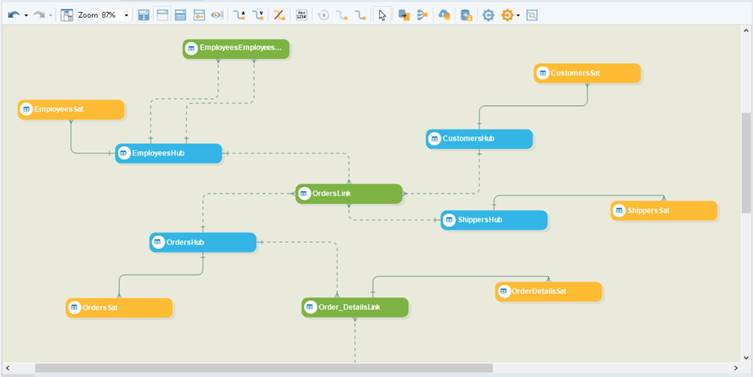
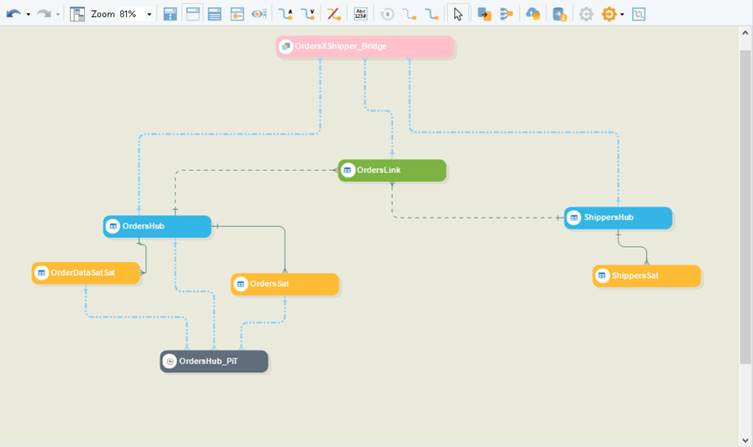
The Business Vault layer contains objects that make querying easier and faster in a Data Vault, while also allowing for easier data loads into the Information Vault layer. It is at this stage where Soft Business rules are also applied. Some business vault entities include Bridge tables, Point-In-Time (PIT) tables, etc. These are loaded using data from the Raw Vault layer, which can be dropped and recreated at any time.
The Information Vault or presentation layer is a subject-oriented, user-friendly layer built on top of Raw and Business Vault layers, making data access easier for reporting, analytics or dashboarding. They are mostly in the form of aggregated denormalized tables, star schemas, or Dimensional models.