Denormalize Transformation¶
Denormalize¶
Many-to-One mapping, also known as ‘pivoting’ or ‘denormalizing’, allows you to combine a number of records into a single record. Denormalizing is useful for reducing the number of tables in the schema, which simplifies querying and possibly improves reading performance.
Sample¶
Steps¶
To add a Denormalize transformation, drag the Denormalize object from the Transformations group in the Flow toolbox and drop it on the dataflow.
An example of what a Denormalize object might look like is shown below.
To configure the properties of a Denormalize object after it was added to the dataflow, right-click on it and select Properties from the context menu. The following properties are available:
Meta Object Builder screen:
Meta Object Builder screen is used to add or remove fields in the field layout, as well as select their data type. The fields added in Meta Object Builder will show in the Output node inside the object box, as well as in all Input nodes corresponding to the number of mapping groups created (see below), with the exception of the key field(s).
Denormalize (Many-to-One) Transformation Properties screen:
Using Select Keys dropdown, select the field or fields that uniquely identify the record. These keys will be used to match the records between the normalized source and the denormalized destination.
Sort Input. Turn this option on only if the values in the matching field (or fields) are not already sorted.
Driver Key Value. Enter the pivot values for your Denormalize transformation. Using the example below, the pivot values would be City, State, Federal, and Country.
Note: Entering driver key values is required prior to mapping the Denormalize object. For each entry in the Driver Key Value grid, a new Input mapping group is created in the object box.
General Options screen:
This screen shares the options common to most objects on the dataflow:
Clear Incoming Record Messages
When this option is on, any messages coming in from objects preceding the current object will be cleared. This is useful when you need to capture record messages in the log generated by the current object and filter out any record messages generated earlier in the dataflow.
Do Not Process Records with Errors
When this option is on, records with errors will not be output by the object. When this option is off, records with errors will be output by the object, and a record message will be attached to the record. This record message can then feed into downstream objects on the dataflow, for example a destination file that will capture record messages, or a log that will capture the messages and as well as collect their statistics.
The Comments input allows you to enter comments associated with this object.
Usage¶
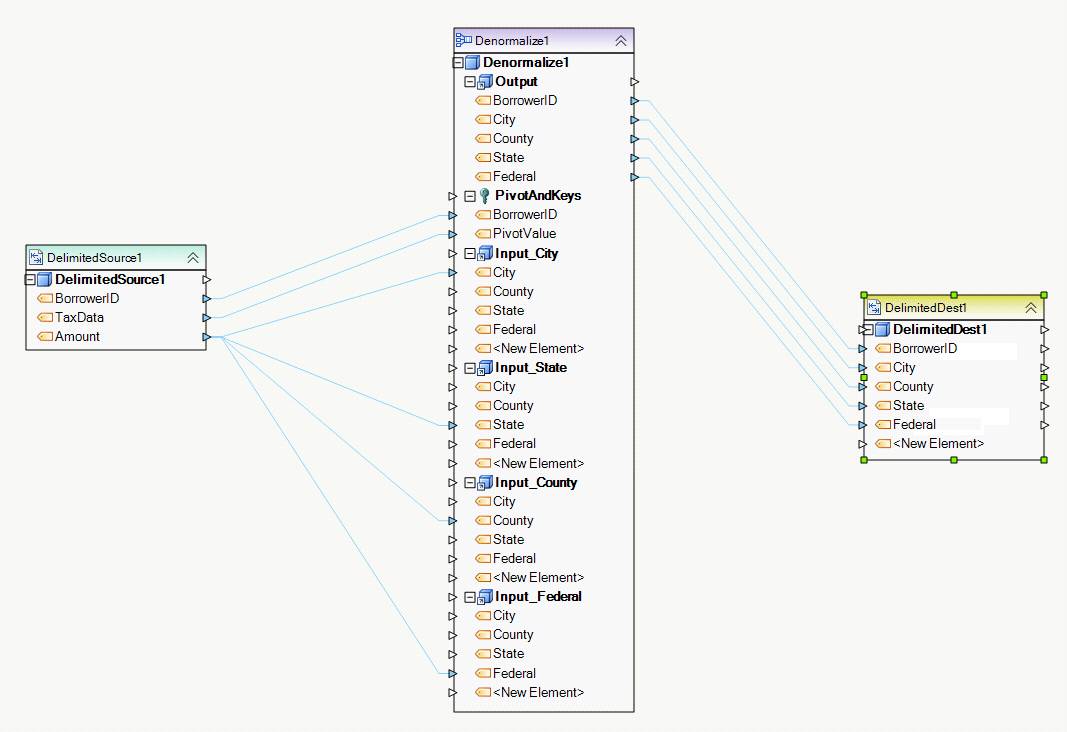
An example of mapping the Denormalize object in a way that achieves many-to-one transformation is shown below. In this example, the normalized recordset from a delimited source file is denormalized by Denormalize1 transformation. The BorrowerID field has keys for identifying and matching records. The TaxData field, which takes the value of ‘City’, ‘County’, ‘State’, or ‘Federal’, is the pivot field. Depending on the TaxData value, the appropriate field in the destination DelimitedDest1 object is populated with the Amount value. This is achieved by means of four mapping groups that make up the Denormalize1 object.