What’s New in Astera Centerprise 7.6¶
Astera Centerprise 7.6 is shipped with new features and capabilities, as well as some key improvements to the existing functionality. Below is a short summary of what is included in this release.
What’s New?¶
A new transformation is added to the transformations library – Data Cleanse Transformation. It enables you to cleanse and prepare your data for further usage.
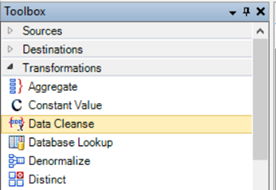
You can perform all sorts of data cleansing tasks such as removing whitespaces, unnecessary letters and digits, or any other specified characters. You can even perform a find-and-replace action on your data set, or change strings to lower/uppercase as needed.
Data Cleanse transformation has replaced ApplyToAll transformation which was available in previous versions of Centerprise. Existing flows will continue to work as is, and do not need any modifications after the upgrade.
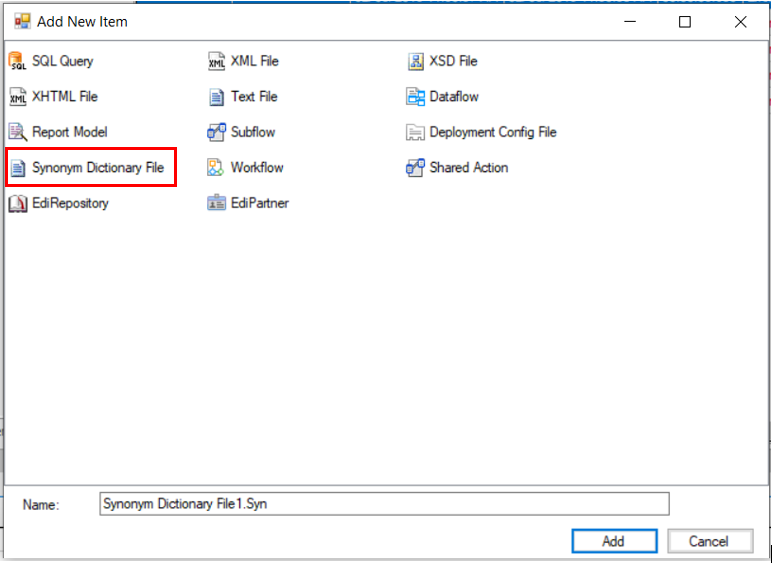
It is common to run into cases where you are dealing with alternate headers. For instance, a Product ID field can be defined in multiple ways in the incoming data sets. It can be called ProductID, Productid, Prod_ID or any other variation of it. You can now create a Synonym Dictionary File in a project to store these alternate header values and Astera Centerprise will match these variations at run-time to map the incoming data.
You can also do synonym-based mapping of the fields that have different names in the two objects by defining them in the dictionary and then using the Shift key while adding the maps.
A synonym dictionary file is a simple text-based file where you can define values in a pipe-separated format, and it can be used across multiple dataflows and workflows in a project. To add a synonym dictionary file, right-click on the project folder in the Project Explorer window > Add New Item > Synonym Dictionary File.
- Built-in Job Optimizer
Centerprise 7.6 introduces Job Optimizer that is designed to optimize and modify the flow at run-time with the goal of improving dataflow performance and decreasing running times and optimizing CPU, RAM, disk and network utilization. Job Optimizer, for example, can remove unnecessary sort operations from the dataflow when the data has previously been sorted, which can dramatically improve flow running time. Conversely, Job Optimizer can add ORDER BY clause on database sources where needed so that the sorting takes place in the database as opposed to on the ETL server.
In addition, Job Optimizer shows suggestions in the job trace to help the user further optimize the flow. An example below shows how Job Optimizer presents optimization improvements and suggestions in the job trace.

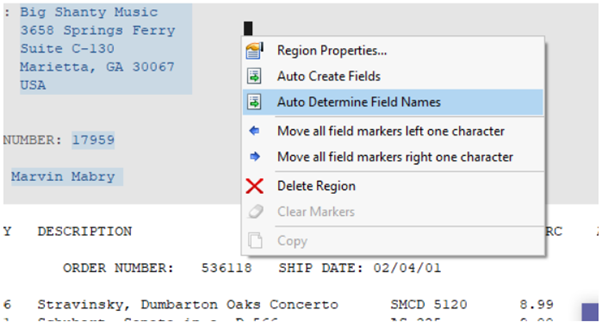
- Auto-determining field names for report models
This new feature automatically detects the header name for each column of the data region from the source file loaded into a report model. To work with it, select the desired field, right-click on it and Auto Determine Field Names.
What’s Improved?¶
- Workflow performance and reliability
We have made some key improvements to the Astera server code to enhance the reliability and performance of workflows. Additional safeguards have been added to the workflow logic to make sure that workflows never get stuck in Running state even in the case of transient communication errors between the cluster servers and the repository database. Workflow completion times have also improved significantly as a result of these changes.
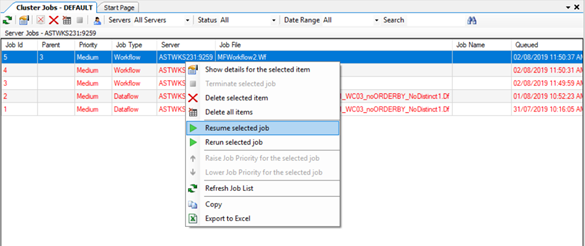
- Improvements in Resume and Terminate functionalities in the workflow
In the case of nested workflows and processes, if a child process (dataflow or workflow) returns an error and is not executed completely, the parent flow will automatically get terminated. Similarly, if a child flow is resumed then the parent flow will also be resumed automatically. Moreover, you now have the option to either resume your selected workflow from where it was terminated or rerun the entire flow from the beginning.
To access the option, go to View > Monitor and right-click on the selected workflow job.
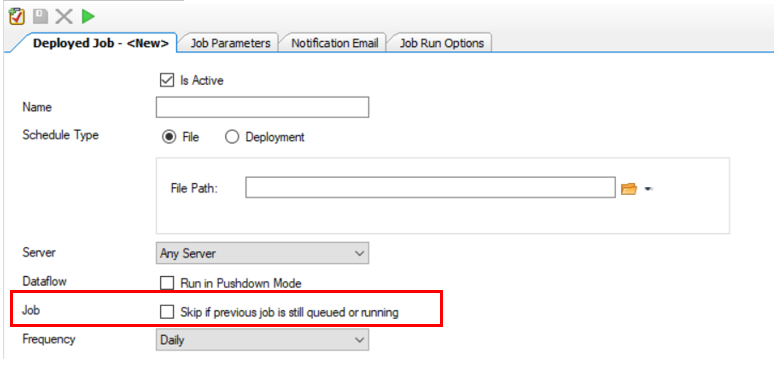
- New features in the Scheduler
A new option is added to the Scheduler which lets you skip a new instance of a job if the previous instance is still queued or running. This prevents multiple instances of the same job from queuing in the case of a busy server.
Continuous schedule code has been revised with the goal of improving the reliability and performance of Continuous schedules, especially when running a busy server with multiple schedule types present. A minimum delay of 5 seconds is now required between continuous schedule runs. This is done to make sure the continuous schedule doesn’t get in the way of other schedules competing for the server resources.
- Improvements to the Monitoring window
Centerprise 7.6 significantly improves UI response times when displaying and navigating long traces. This in turns help optimize the flow performance of the flows generating large trace output due to reduced database contention when reading and writing to the trace tables. In addition, the Monitoring window has a new Refresh button on the monitoring toolbar, which shows a snapshot of the current job status when the trace is paused.
Read more about the job trace improvements in Centerprise.
- New server configuration keys to improve flow performance when sorting large datasets
Centerprise 7.6 has a new Sort algorithm that is designed to optimize RAM and CPU use when performing sort operations on large datasets. This new model can bring about significant performance gains in certain scenarios. In addition, the server administrator is able to further optimize sort performance by modifying the additional configuration keys for Sort in ServerAdminConfig.xml file. Changing these settings can improve the performance of sorting operations by allowing the server to allocate more RAM if needed. Changing these values is recommended only if adequate RAM is available to the server during flow run-time.