Cardinality Errors FAQs¶
Question 1: “While using Route component I received the following error. Why am I getting this error?”
Message: Cardinality of element paths inconsistent with other source paths
If you look at the dataflow below, you have a map going from ExcelSource 1 directly to Database Destination1. You also have a map going from the same source to a Router and then the database destination. This combination of maps will result in a cardinality error during flow verification or when you run the flow.
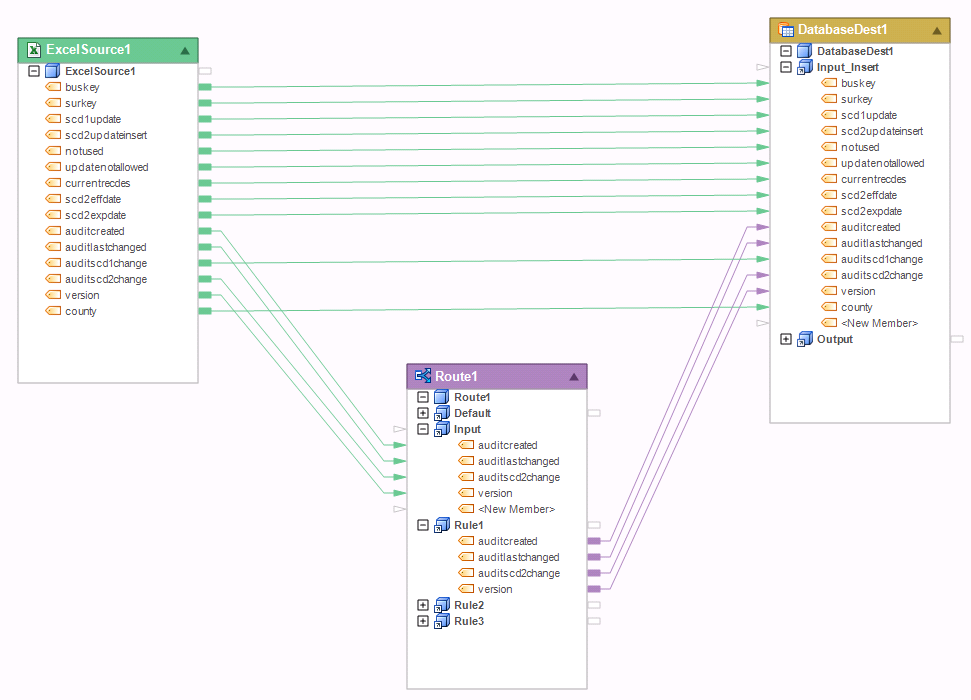
The reason behind the error is a possible mismatch in the number of records going out of Route1 and ExcelSource1. The Route transformation is for routing entire records, not values, and it could also route fewer records than the input set through the Rule1 path (because not all of those records will meet the criteria in Rule1). As a result, it is not possible to reconcile those few records with the records flowing directly from ExcelSource1 into the database table.
You will also run into a cardinality error when trying to do this with any Set transformation. This is because a Set transformation, which works on the entire set of data, could change the order, filter, aggregate or otherwise change the input set, increasing or reducing the number of records compared to the input set. For example, if you have a Filter transformation instead of a Router in the dataflow above and filtered out all but 1 record out of 10 coming from the Excel workbook. From the point of view of the destination table, how many records should it write? 1 or 10? The counts don’t match up, and this is the reason you get a cardinality error. To avoid this error, a record must flow entirely through the Set transformation (e.g. Route or Filter).
Question 2: My source data has a complex structure. I need to extract some inner loops from the source file and save the output in a comma separated file for processing by a downstream application. How do I do this without running into a cardinality error?
This question is frequently asked by our users who need to extract data from hierarchical files with a complex layout, such as EDI, XML or Report documents, to name a few.
An example of such an input file is shown below. This dataflow reads an EDI source file with patient eligibility data. The source file has a very complex layout, resembling a tree with a lot of levels. There are loops at many different levels in the layout, which return a collection of records in a node. In this example, we need to extract data from two nodes, EB and DTP. The EB node is shown with the ![]() icon in the tree. This means that it is a single instance item under its parent node, LOOP_2110C. In a single instance node, each occurrence of LOOP_2110C loop will have no more than one EB record in it.
icon in the tree. This means that it is a single instance item under its parent node, LOOP_2110C. In a single instance node, each occurrence of LOOP_2110C loop will have no more than one EB record in it.
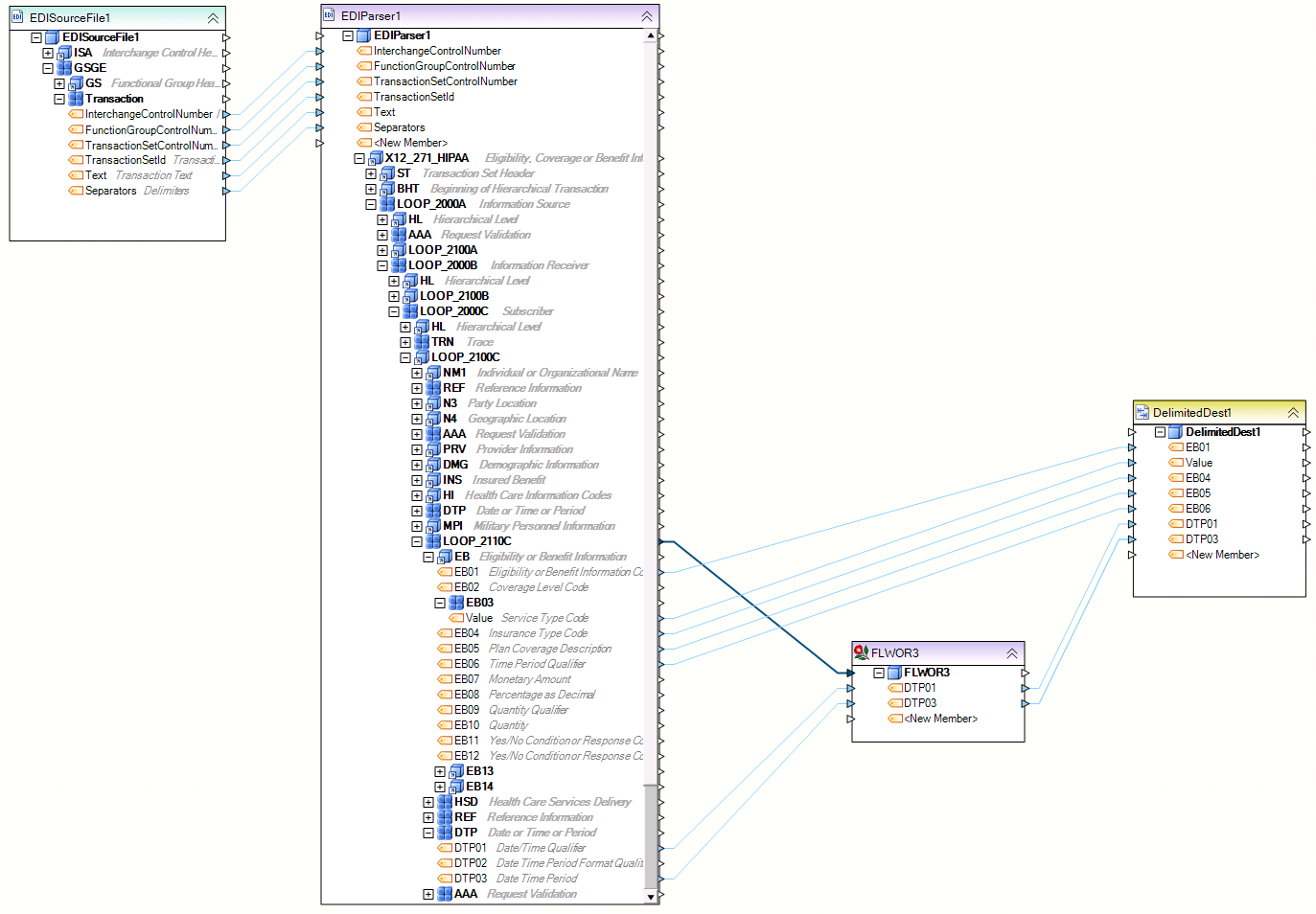
EB also has a child node, EB03, which is a collection. Collections are shown using icon on the tree. This means that there could be many EB03 records within each parent EB record.
The other node we are extracting data from, DTP node, is also a collection.
So we have two collections from which we need to extract the field values. Because each of the two collections may return a different number of records compared to the other collection, we cannot combine the fields from both collections, EB1, EB2, Value, EB4, EB5, EB6, DTP1 and DTP3, in a single output file. This would create a many-to-many cardinality and as a result, a cardinality error. Note: For a detailed discussion of cardinality types and best practices to avoid cardinality issues, see Cardinality article.
To avoid the cardinality error in this scenario, we need to transform the many-to-many cardinality using a Flower transformation, for example.
Flower transformation can eliminate a many-to-many cardinality, which would normally be the case when joining two sibling collections, by reducing one of the collections to a single record using the logic defined in the Flower. In our example, the Flower object acts as a filter returning the first record from the DTP collection in each LOOP_2110C record. Notice a scope map into the Flower object shown as a blue line connecting the LOOP_2110C loop. This tells the dataflow engine to ‘scope’ the collection at that level. Because the Flower object returns 1 record from DTP collection for each LOOP_2110C record, this effectively creates a 1:Many relationship between DTP and EB. This relationship can be saved in the destination file by de-normalizing the dataset, which repeats the single DTP record for each EB record.
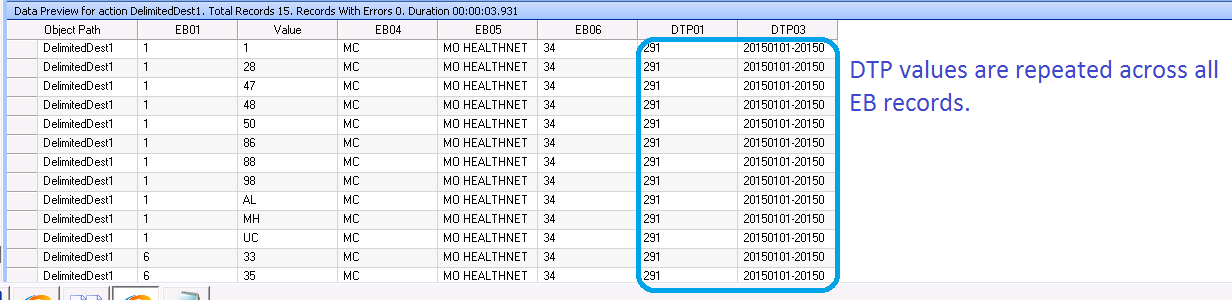
A sample dataset using this transformation is shown below.
Question 3: “I am getting a cardinality error when running the dataflow. How can I modify my dataflow to avoid the error?”
Message: Cardinality of element paths inconsistent with other source paths
The dataflow shown below tries to achieve a similar goal to the one from Question 2. The flow aims to join the output from two sibling collections, which creates a many-to-many cardinality and an error.
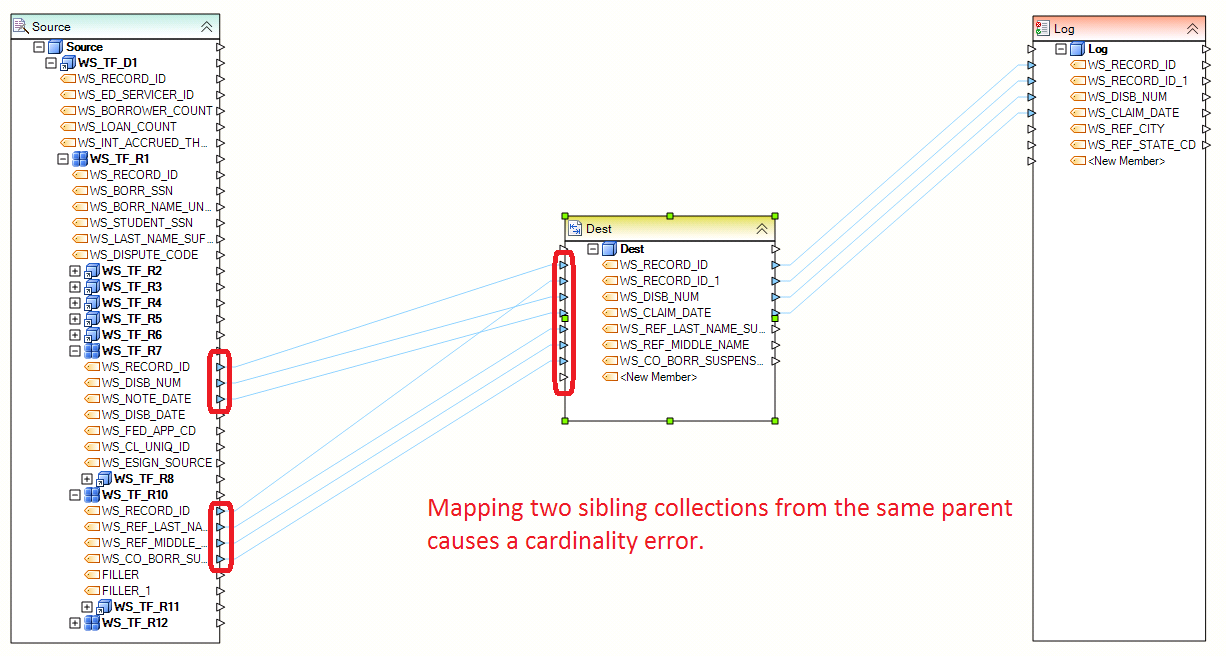
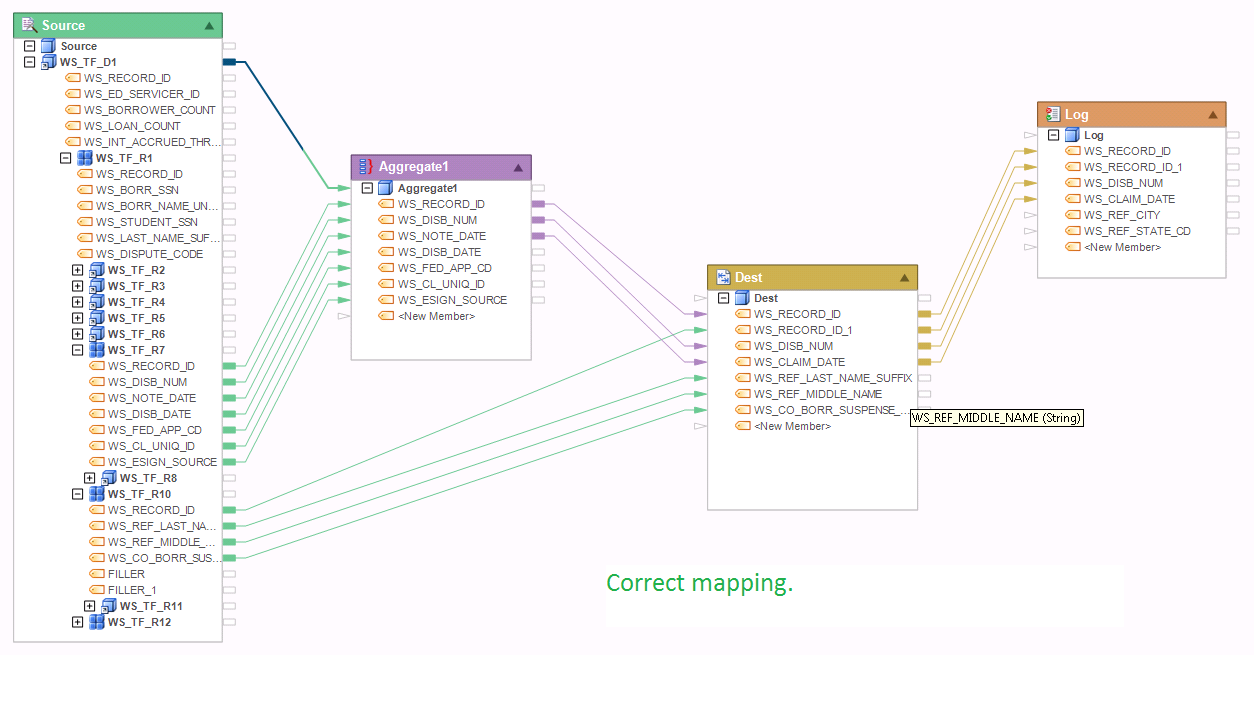
To fix the cardinality error, we need to transform one of the two collections into a single instance while preserving the data that needs to be extracted. In our example, it turns out that the user only needed details of the last claim in the collection of claims. The data from all prior claims was not needed, and so it could be discarded for the purposes of reducing the collection into a single record. So we added an Aggregate transformation returning a Max(WS_NOTE_DATE), as shown in the image below. The Aggregate is scoped at the root level; this is shown on the flow diagram as a blue line connecting the WS_TF_D1 node. The aggregate returns a record with the max disbursement date among all claims in the WS_TF_D1 record, effectively returning one record from each WS_TF_R7 collection. This creates a 1:Many relationship between WS_TF_R7 and WS_TF_R10 which avoids the cardinality error in the same way we described in Question 2.
For more information on Cardinality and ways to address it in your dataflows, see Overview of Cardinality in Data Modeling.