Auto-Parsing¶
Astera ReportMiner allows users to process an input stream of name data and returns it into its constituent elements such as first name, middle name and last name, as parsed output with the help of the built-in auto-parsing feature.
In this document, we will learn how to automatically parse name data fields using the auto-parsing feature in Astera ReportMiner.
Sample Use Case¶
In this case, we have some unstructured data stored in a PDF file.
Download the sample PDF file from here.

This file is a customer list report that contains information such as full contact name, full address and account details of customers.
If you look at it, the Account field contains full name with title. We want to extract and parse this information into Suffix, First Name, Middle Name, Last Name and Prefix.
Creating a Report Model¶
1. Load the unstructured source file in ReportMiner’s designer.
2. Add a data region. Specify the pattern by typing “ACCOUNT:” in the pattern bar.
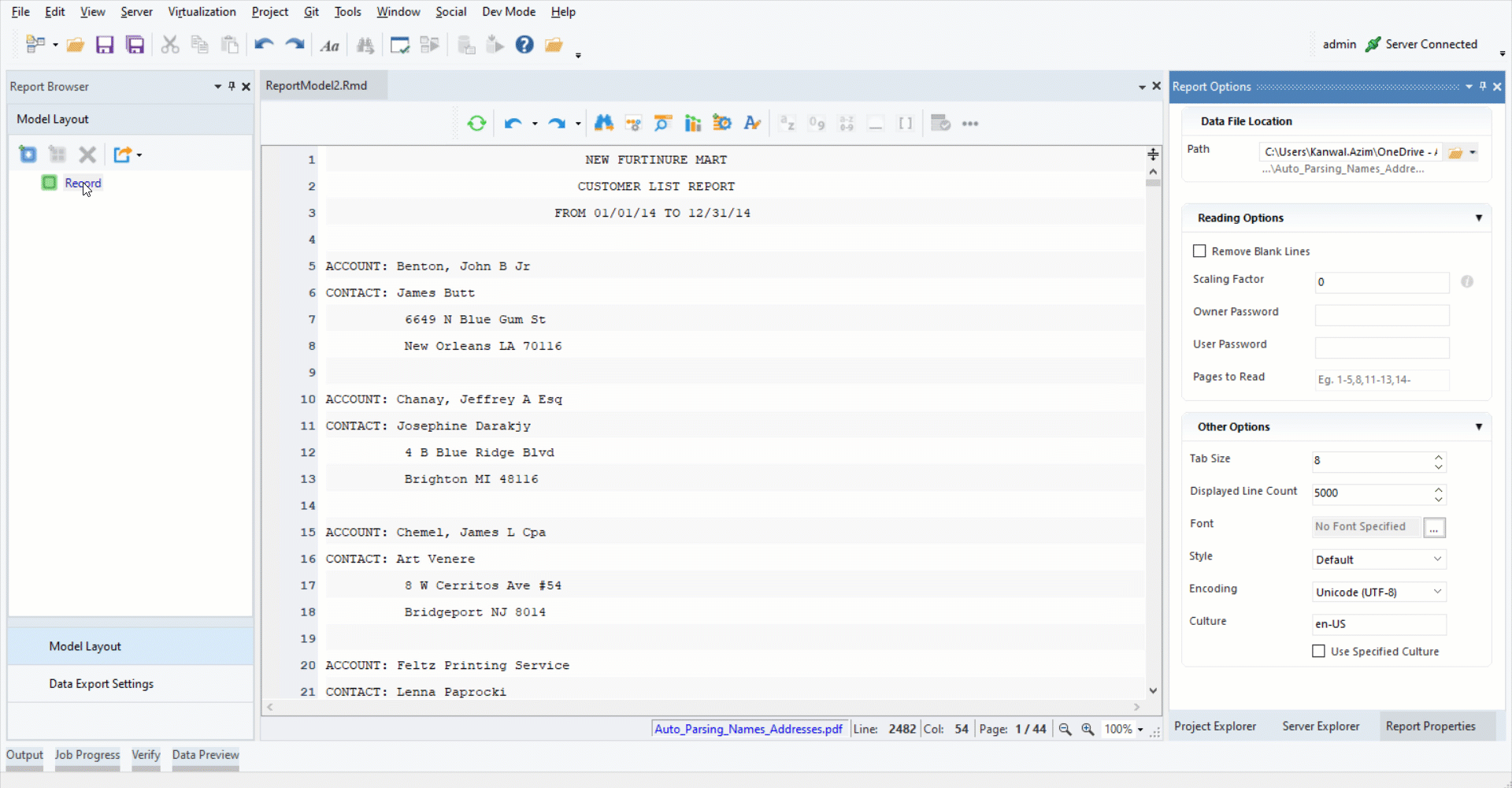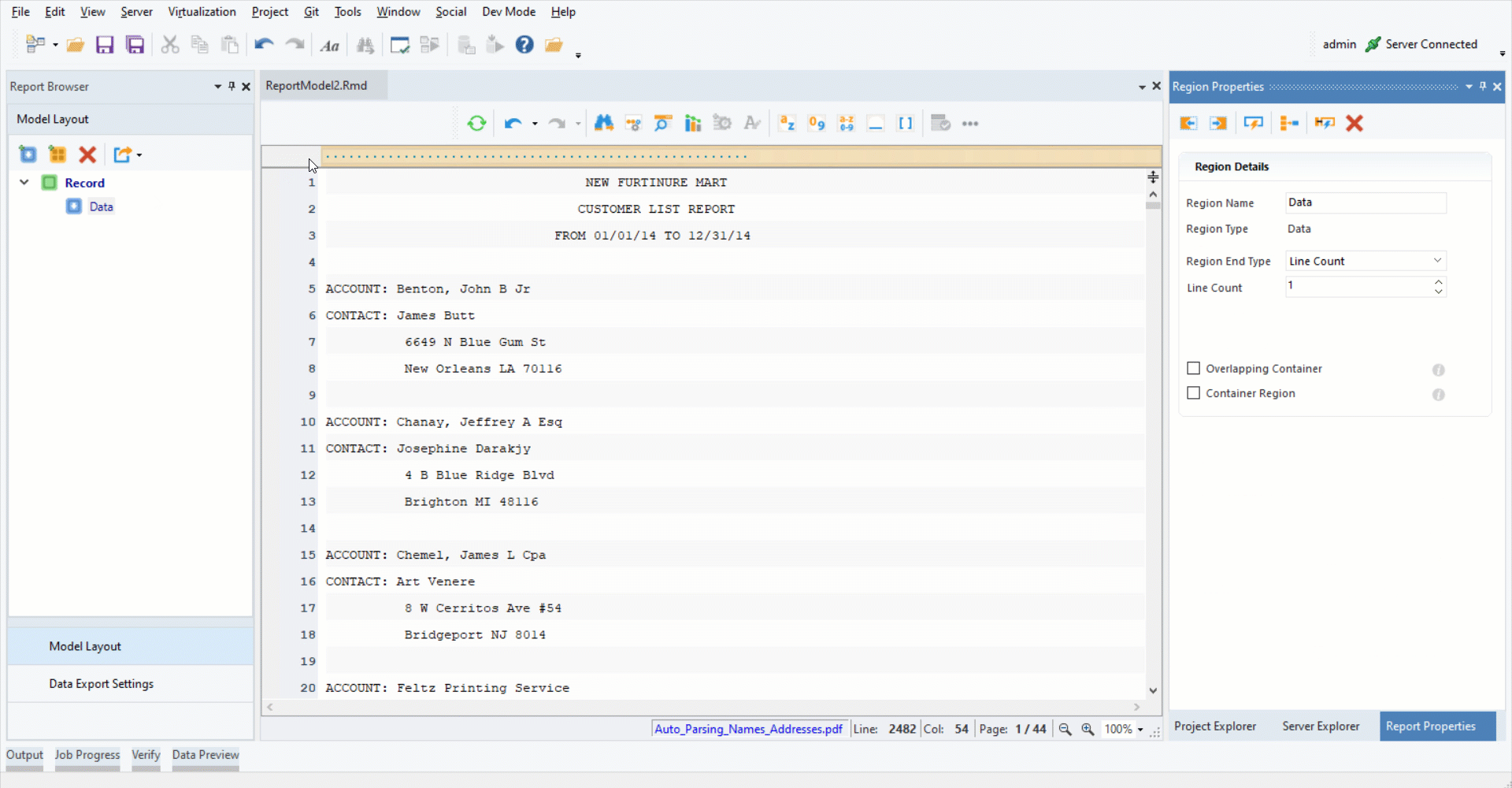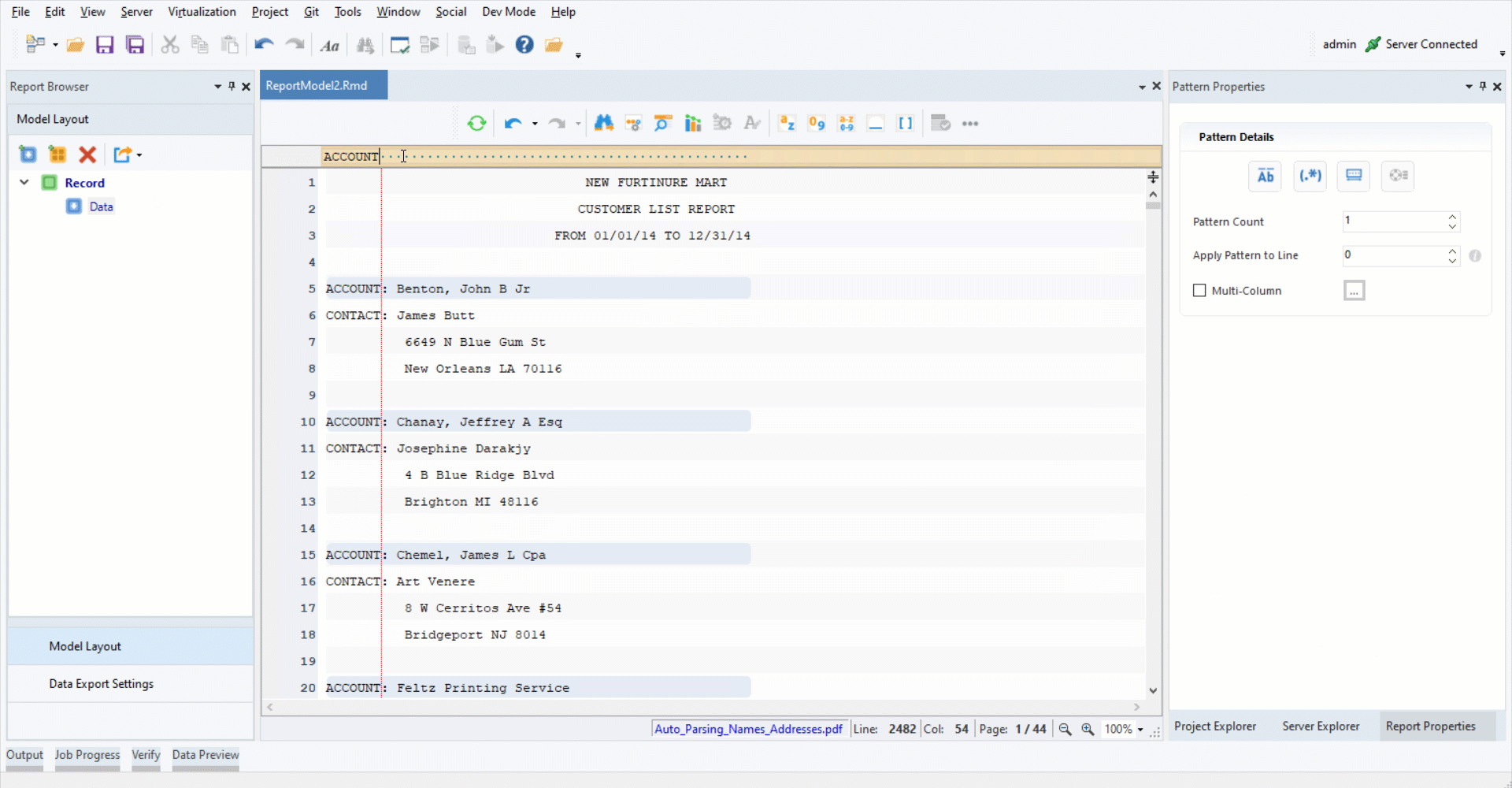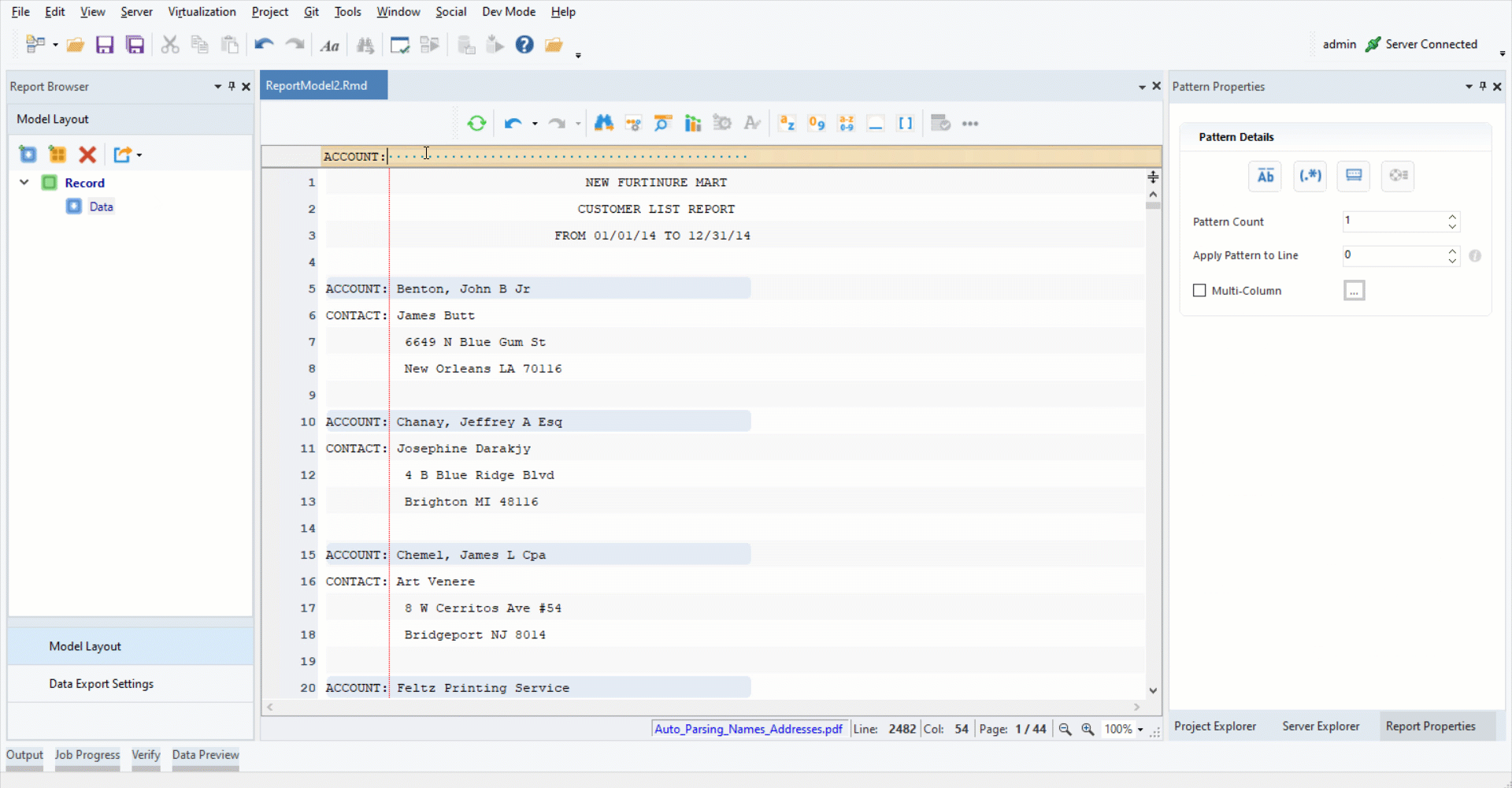
3. Highlight the data region after “ACCOUNT:”. Right-click on it and select Add Name Field from the context menu.
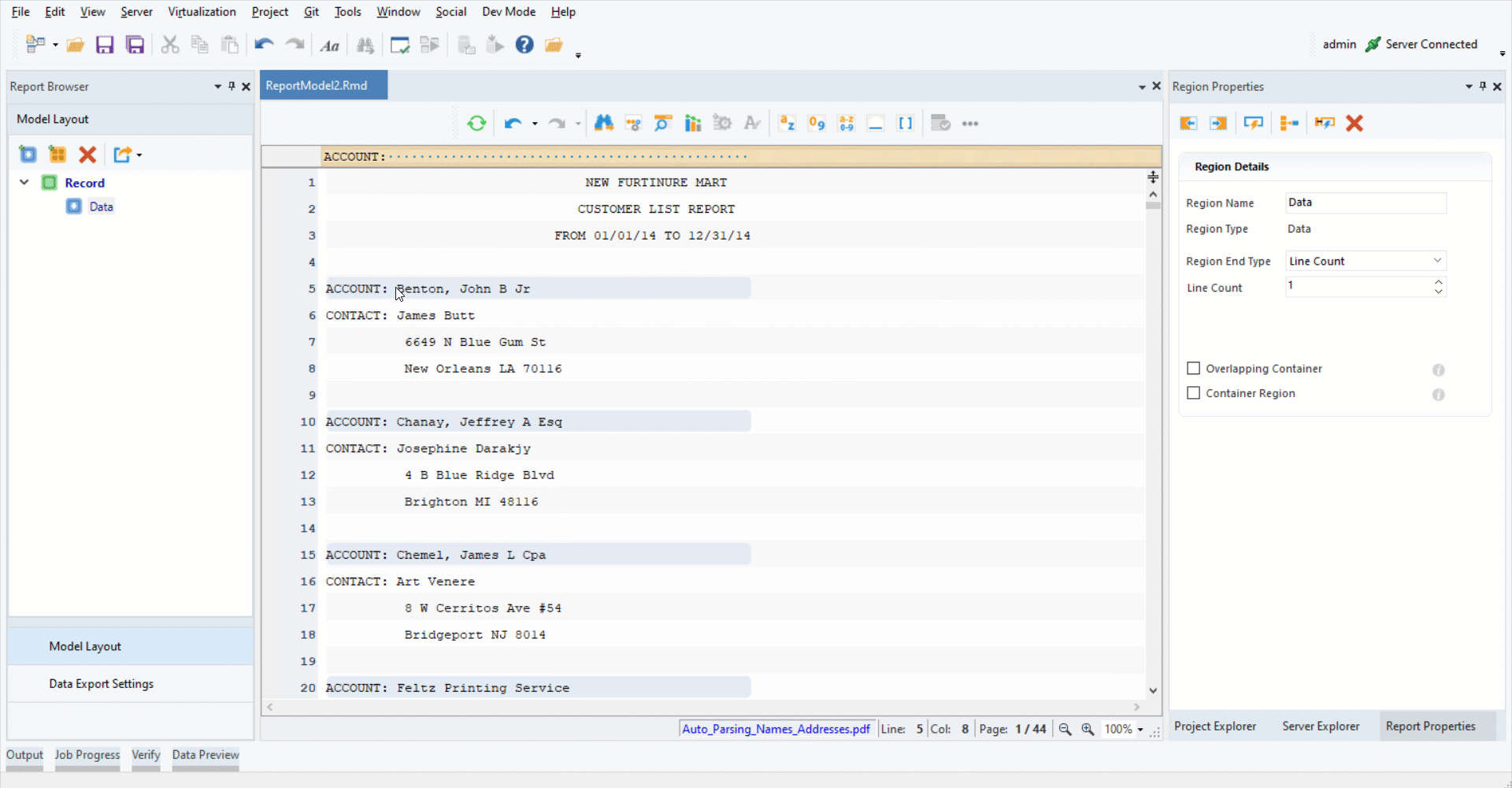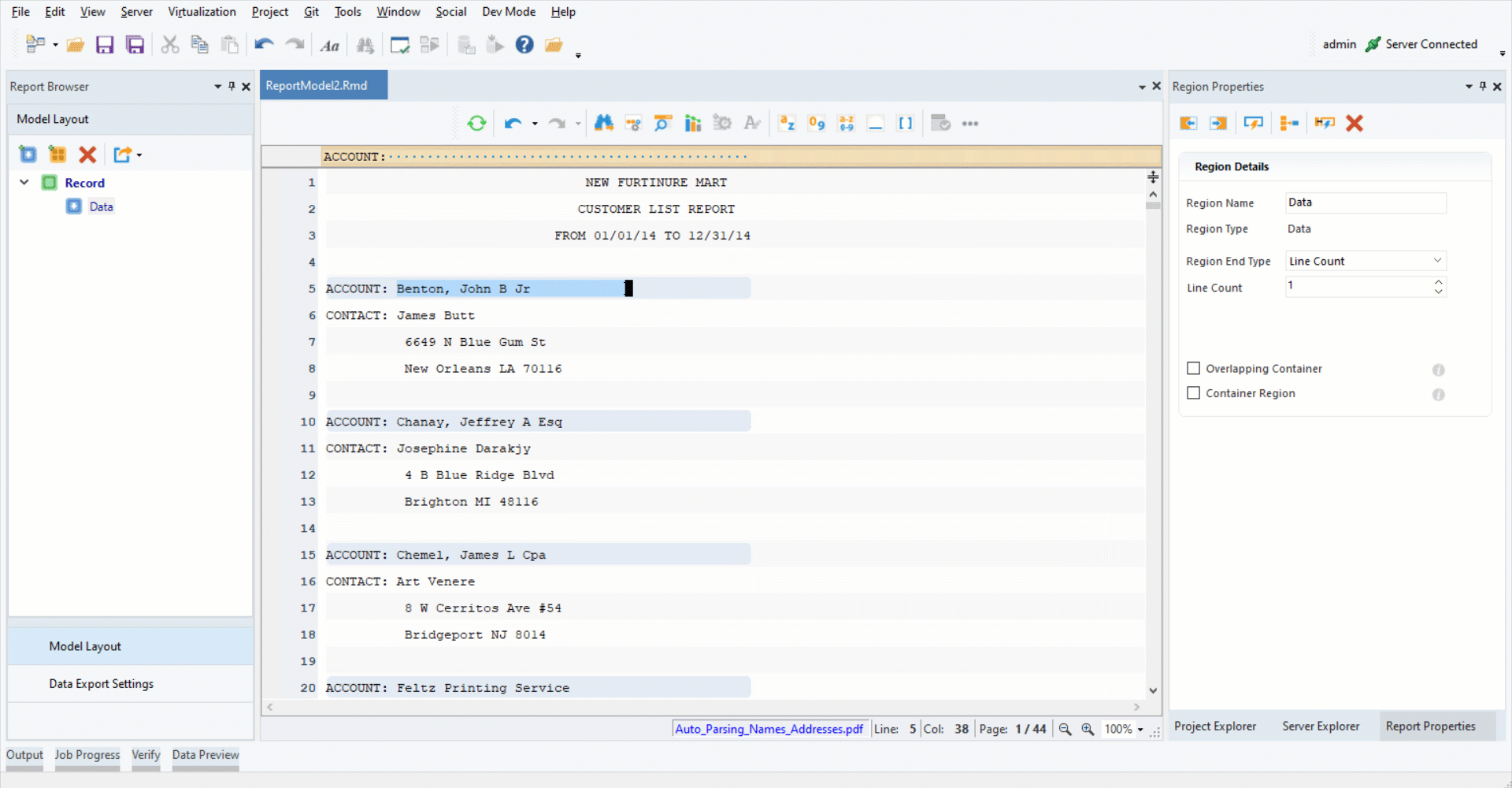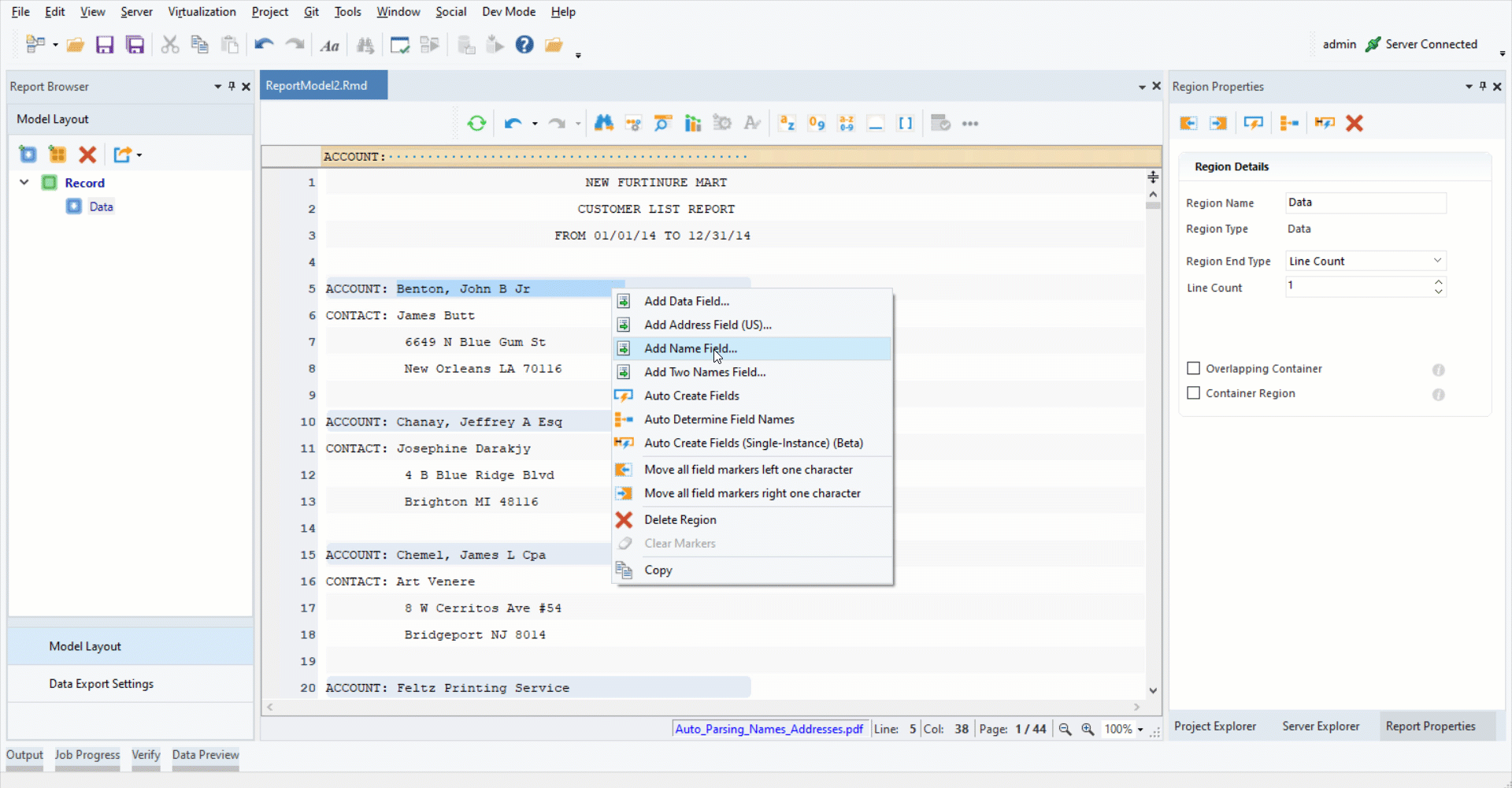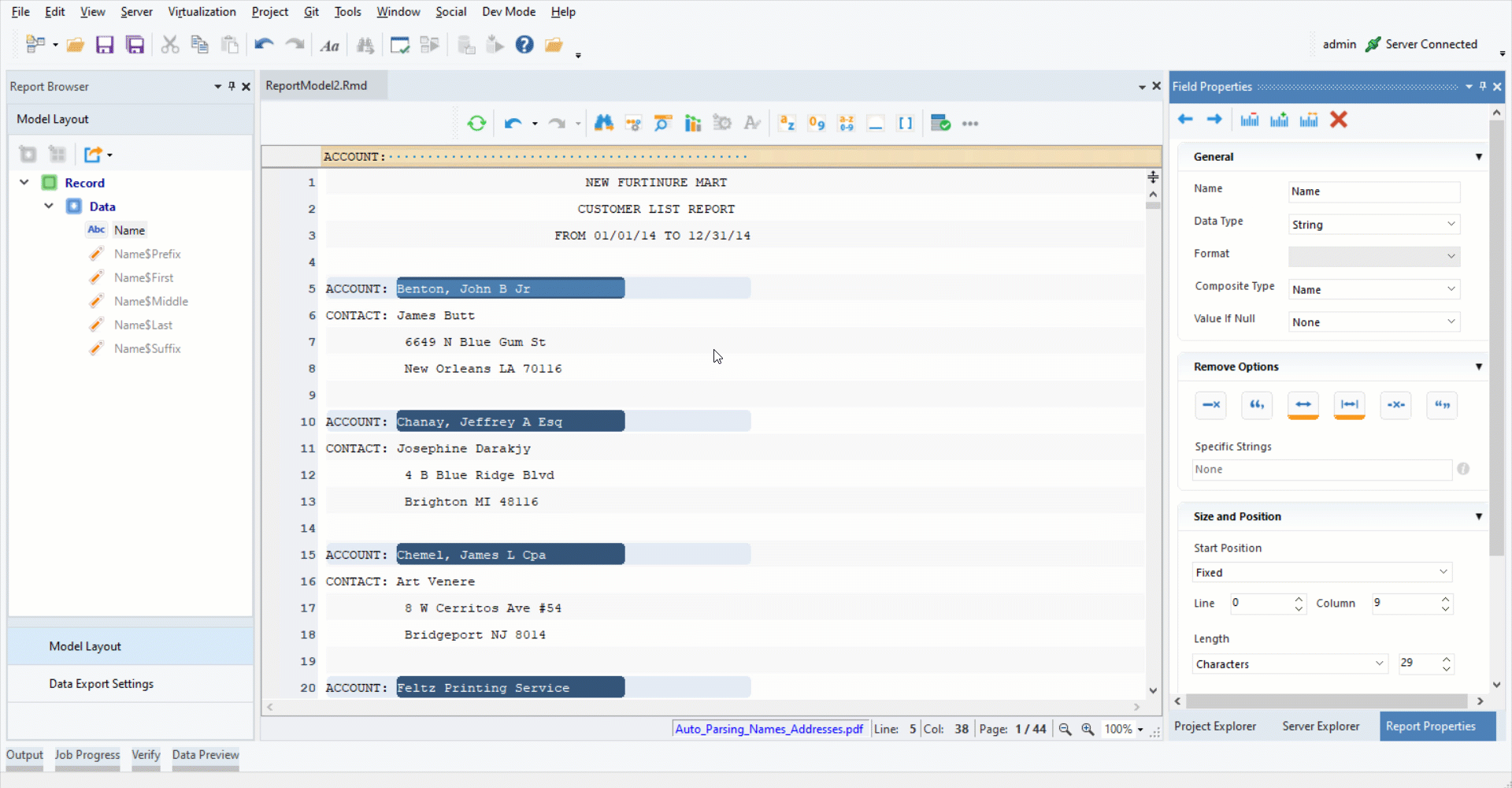
You can see that the parsed name field components such as NamePrefix, NameFirst, NameMiddle and NameLast have been added to the report model in the Model Layout panel under the Report Browser panel.
4. Preview the extracted data to make sure everything, including the different fields and data, is in place.
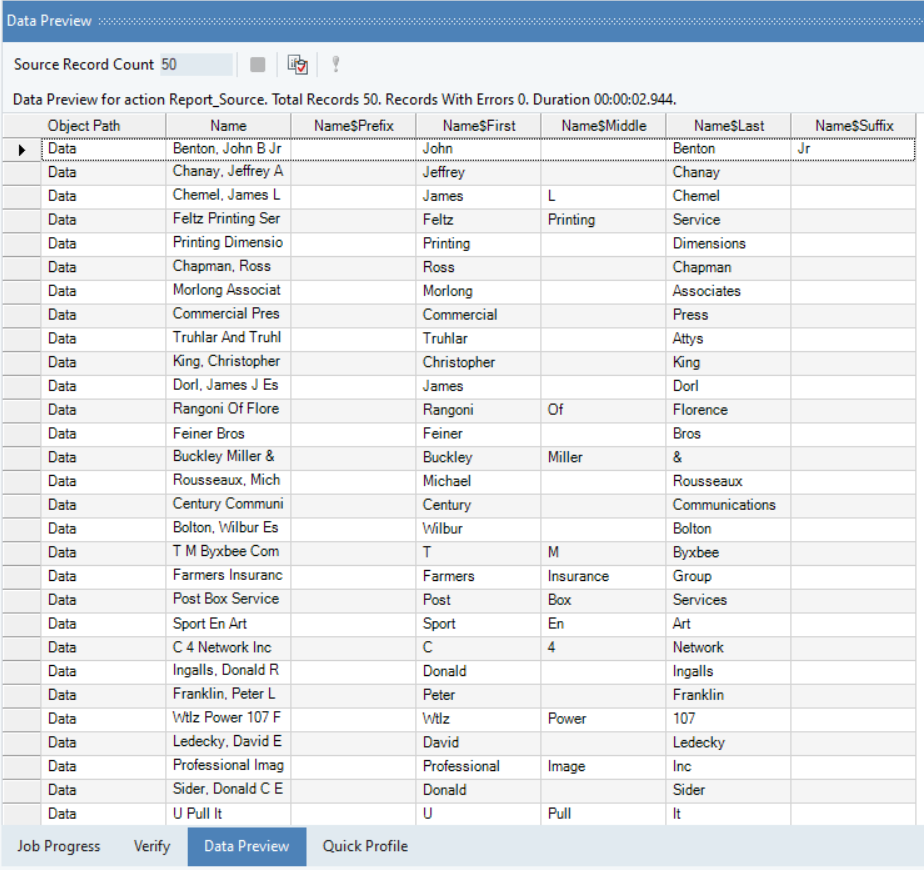
The concludes working with the Auto-Parsing feature in Astera ReportMiner.