Loading PDFs with OCR¶
Astera ReportMiner provides the functionality to extract data from PDFs. There are two types of PDFs that are used, extractable and non-extractable. Extractable files contain text, whereas, the non-extractable PDFs have images or scanned documents saved as PDFs. In order to extract data from these PDFs, Astera ReportMiner provides an option to load these files with Optical Character Recognition (OCR).
Using OCR¶
We have a PDF file which is a scanned copy of an invoice for a consulting service. We will use the OCR option in Astera ReportMiner to extract the data.
1. Go to File > New > Report Model,
Select the PDF and click Open.
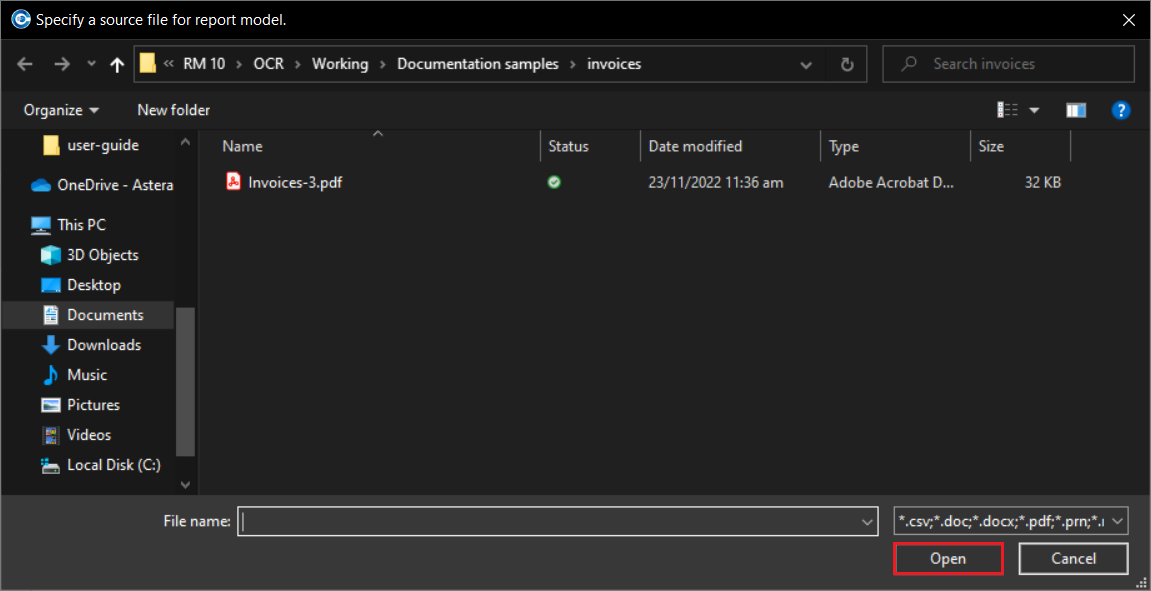
2. As the file does not have text, and is comprised of images, ReportMiner presents it as follows:

Select Use OCR to begin OCR processing on the document.
As the OCR is processed, a green processing bar is shown and if you want to cancel the processing, you can uncheck the Use OCR option in the OCR Options section of the Report Options panel.
4. For the current file read, the OCR gives us the following result:
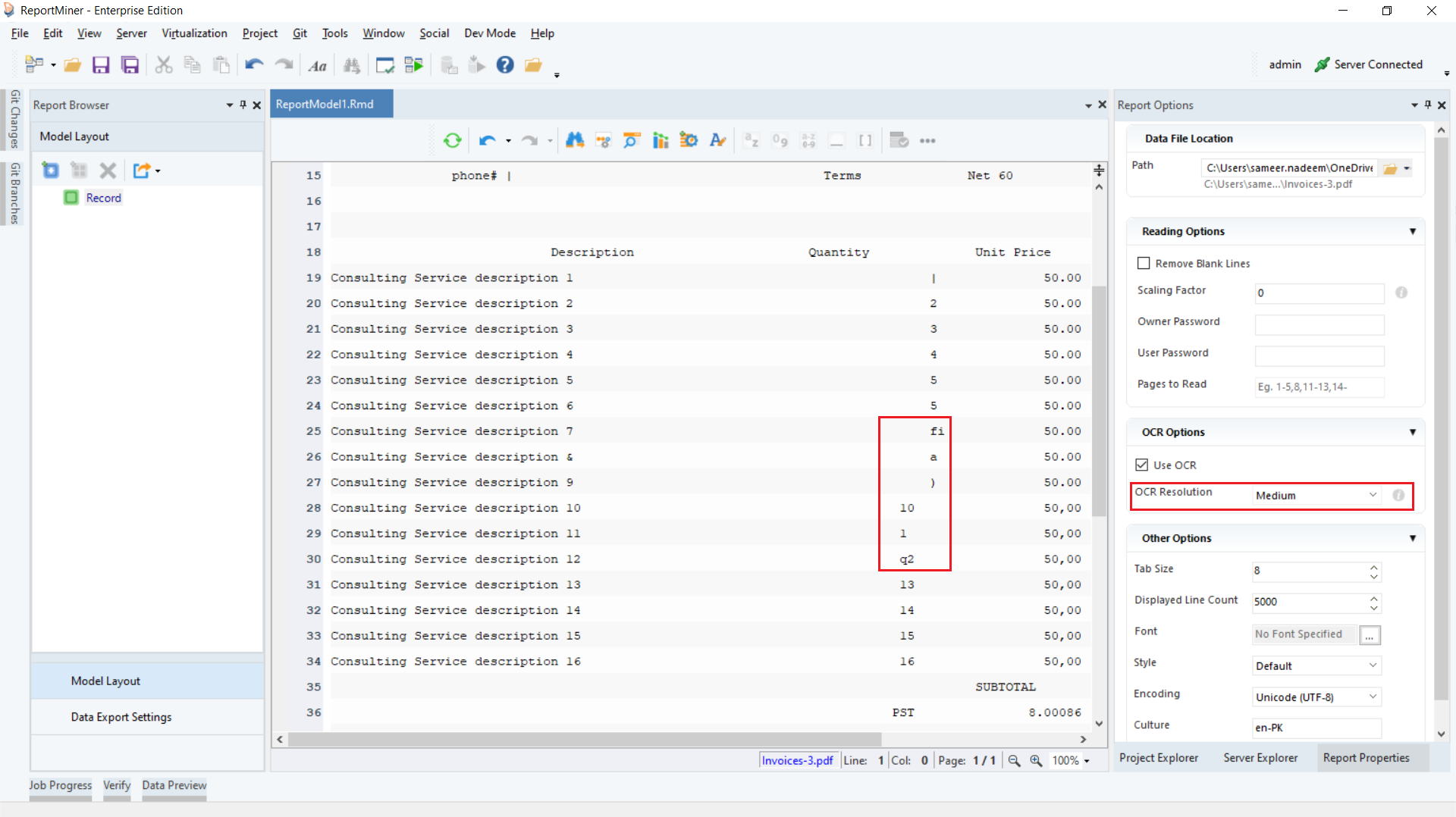
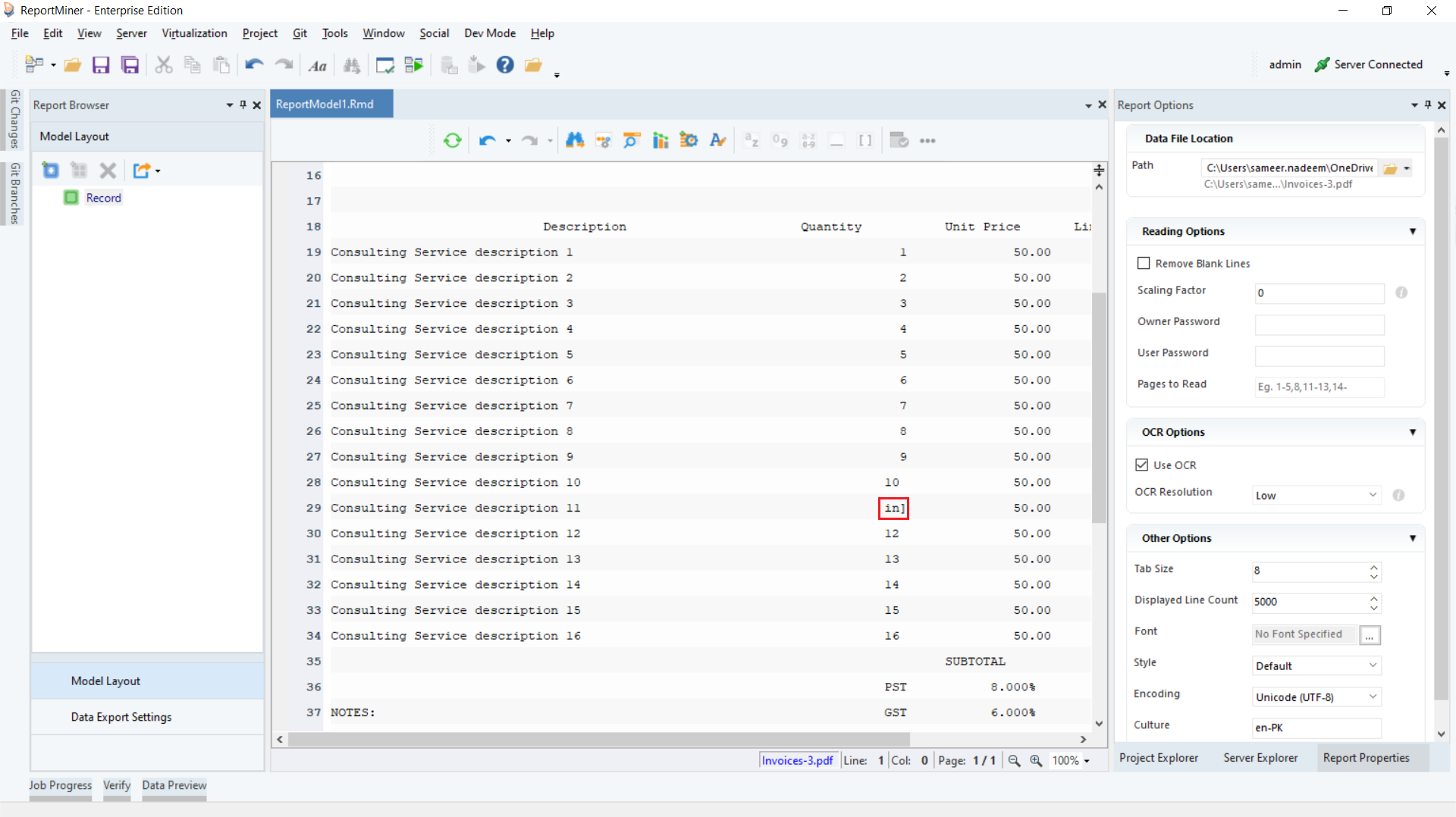
As can be seen, there are a few misread items in the quantity column.
There is another option, OCR Resolution, where the user can select a suitable resolution to apply OCR. In order to determine which option is best for your case, visit the Best Practices for OCR document.
We will select OCR Resolution at low and we get the following result.
5. After processing, the data is presented on the designer. Along with useful data, there are also some noise elements in the original file which are incorrectly converted to text and some erroneous readings of data.
ReportMiner has an Edit Mode to allow the user to edit the extracted data in order to clean and correct the result of OCR.
Click the Start Edit Mode icon on the toolbar above the designer.
6. In the Edit Mode, there is a separate toolbar with tools for editing.
| Icon | Name | Purpose & Functionality |
|---|---|---|
| Save | To save the extracted data to a .txt file. | |
| Find and Replace | To find and/or replace a particular string within the text. | |
| Cut | To cut a particular data to clipboard. | |
| Copy | To copy a particular data to clipboard. | |
| Paste | To paste the last item from the clipboard. | |
| Undo | To undo the previous action taken. | |
| Redo | To redo the undone action. | |
| Revert to Original | To revert the edits back to original. | |
| End Edit Mode | To end Edit Mode and go back to the Report Model. |
We will edit the data in the file to remove the noise elements and correct a few numbers.
7. The editable data can be saved at any point to a .txt file for ease in later use.
8. Once done with the edits, click on the End Edit Mode icon on the toolbar above the designer. After edits, closing the edit mode changes the source file path of the report model to the .txt file we just saved.
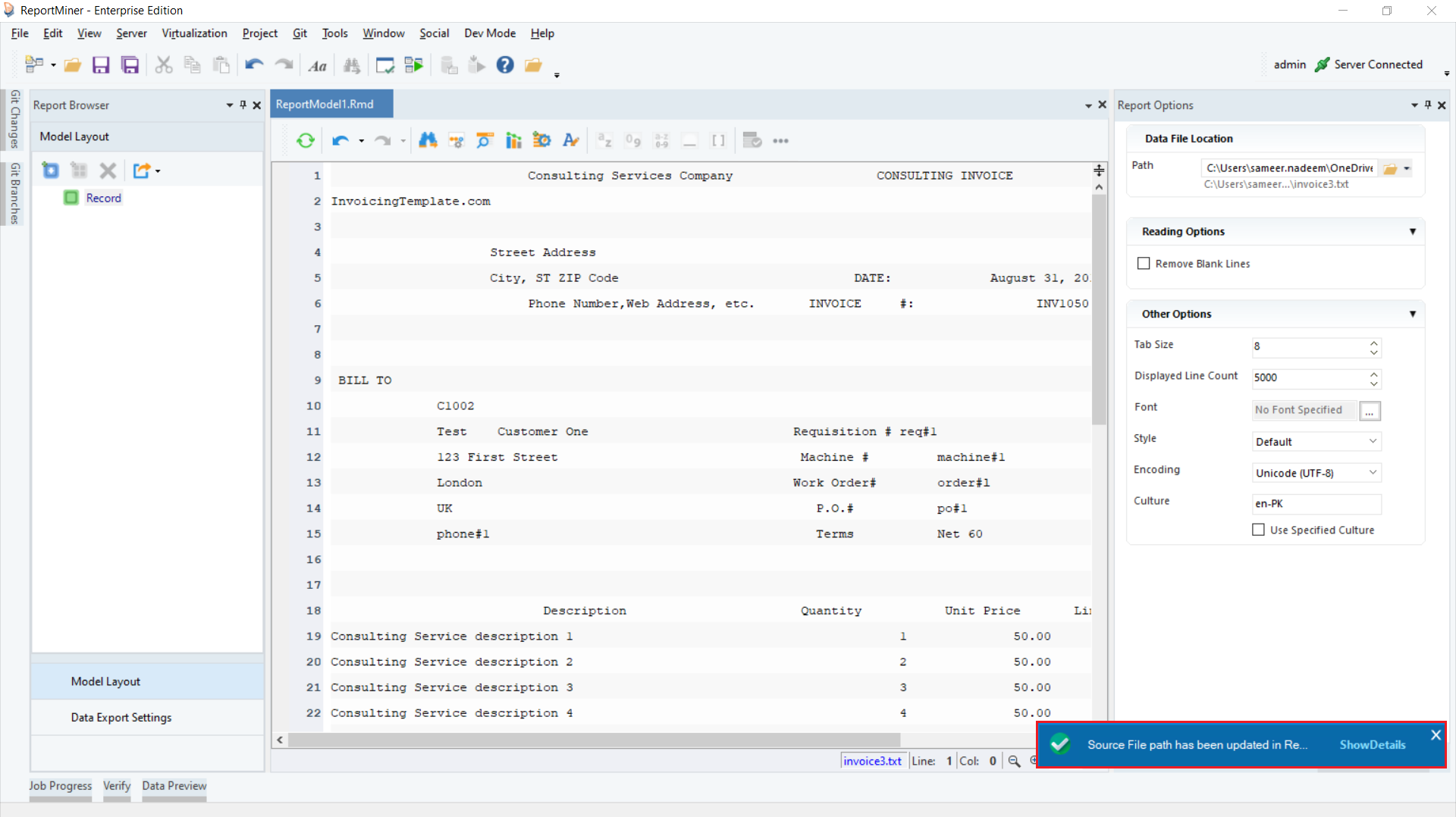
Now, you can proceed to interact with the data on the designer as normal in a Report Model.
This concludes our discussion on the usage of OCR in loading files in Astera ReportMiner.