Data Regions in Astera ReportMiner¶
To extract data from an unstructured document via template-based extraction, it is important to capture the parts of the document from where data can be extracted. In terms of ReportMiner, the area captured within your source report is called a data region.
Creating data regions is the first step in designing a reusable extraction template. An extraction template is called a report model, and data regions are the backbone of report models as they direct ReportMiner where to extract the data from.
Data regions are defined by specifying a pattern and they may span over any number of lines in a source file as per the use-case.
There are different types of data regions, such as header, footer, single-instance, collection, append, and some special regions like name-entity, and table region.
In this article, we will learn about the types of regions and their purpose in Astera ReportMiner.
Header and Footer Region¶
As the name explains, header and footer regions are used to extract the information occurring at the beginning or end of a page. The data extracted in these regions can be a date, page number, author/company name, or any other recurring information at the top/bottom of every page.
Note: It is important to note here that a report model is incomplete without a main data region. So, users must create a main data region first, and then create other types of regions.
In the page 1 of the Orders Report (shown below), the first 3 lines can be extracted in a header region as they contain information about the time, date, from and title of the report. Moreover, these lines occur on every page of the report.
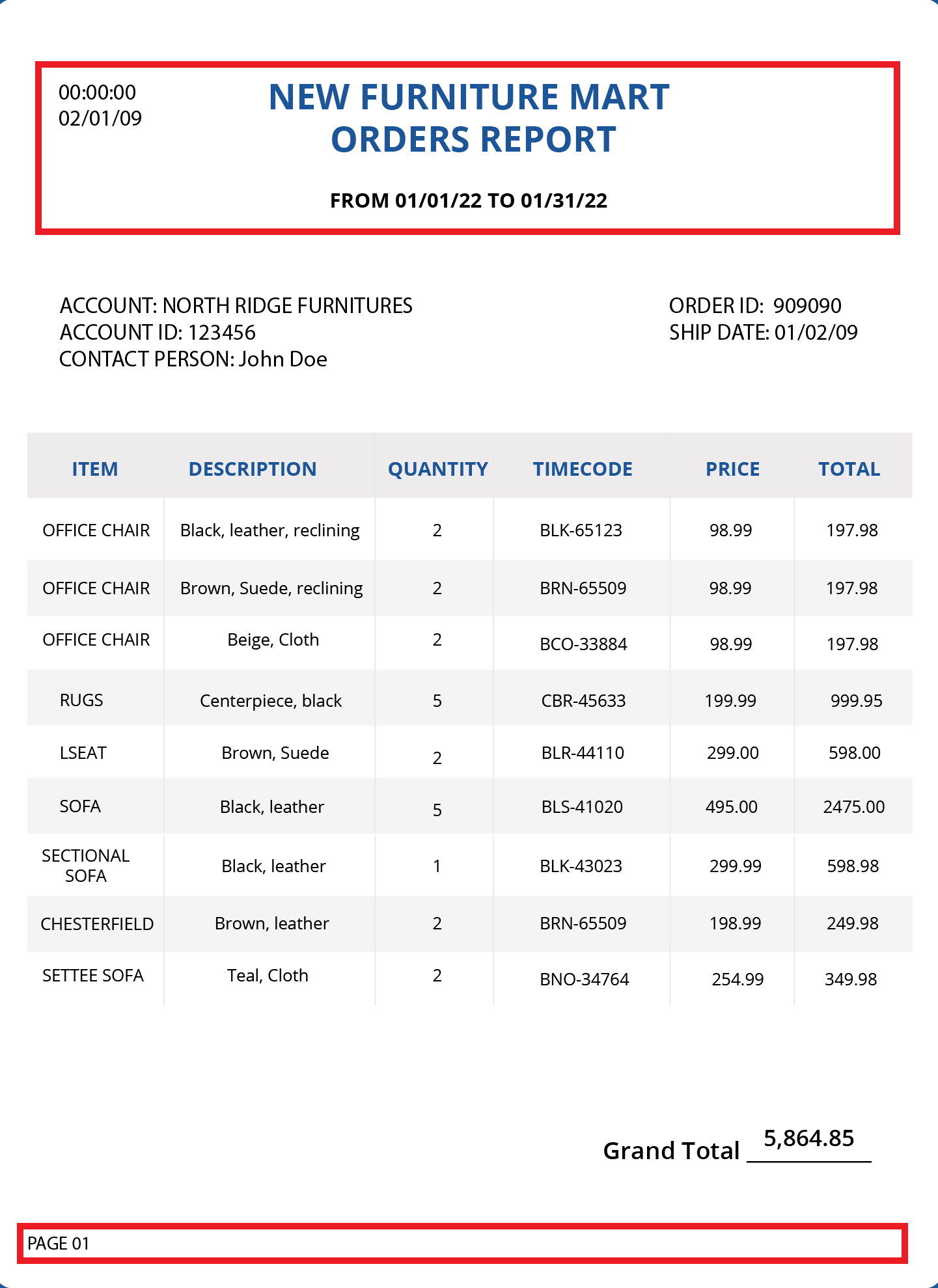
The last line contains the page number, repeating on each page. Therefore, page numbers can be extracted in a footer region.
Single-Instance Data Region¶
A single-instance data region is a sub-region that extracts a single set of data points.
A single-instance data region is used when the relationship between parent and child data regions is a one-to-one relationship. For example, in the sample data of Orders Report, an order can only be placed by one Account. Therefore, we will use single-instance data region to extract the details of the Account from the data source.
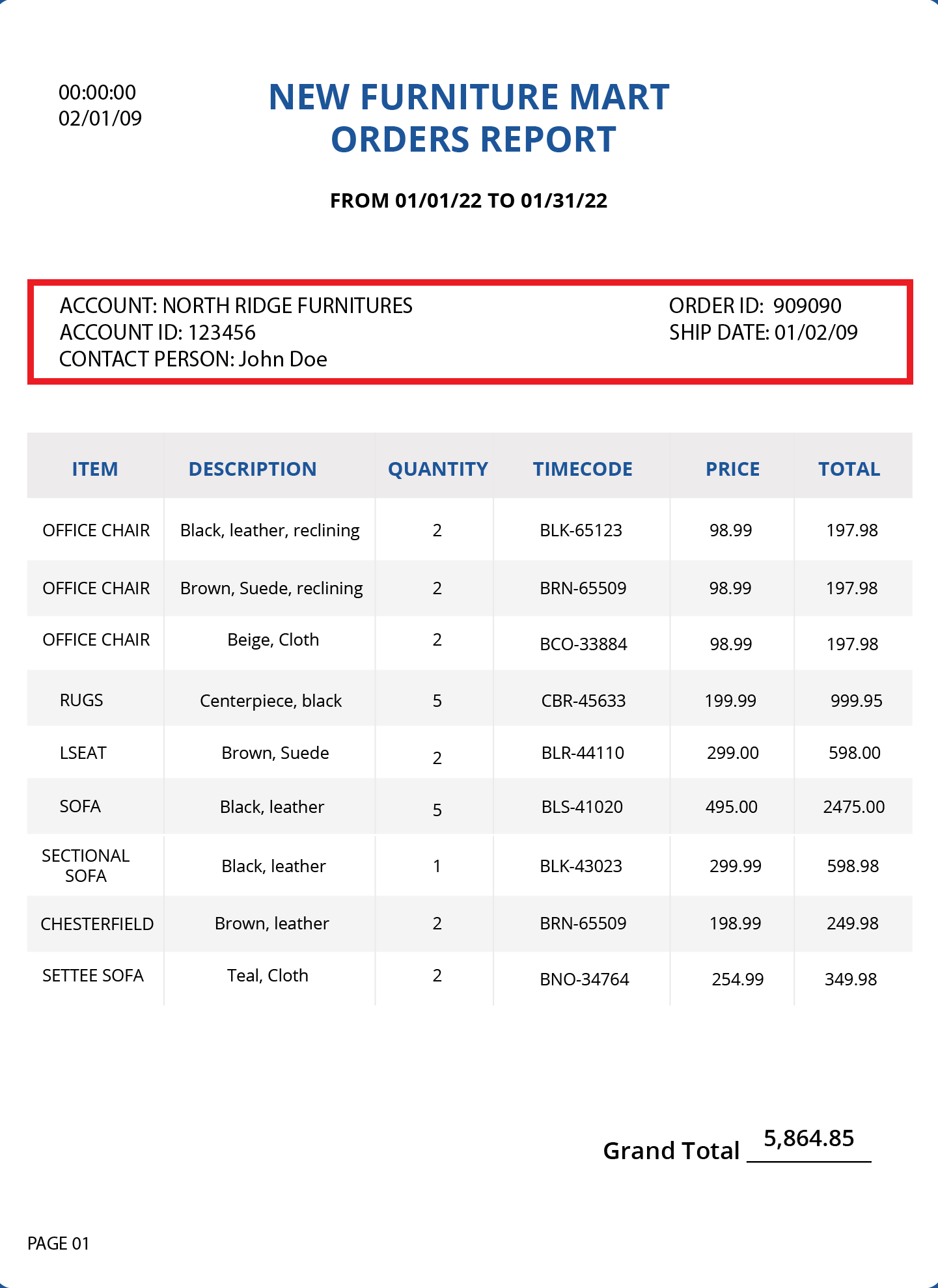
A main data region is always a single-instance data region.
Single-instance data region node has a blue icon in the Model Layout panel.
Collection Data Region¶
A collection data region is a sub-region that extracts multiple set of data points.
We use a collection data region when the relationship between parent and child data regions is a one-to-many relationship. For example, in the same example of Orders Report, there can be multiple items in one order. Therefore, we will use a collection data region to extract details of the items ordered.
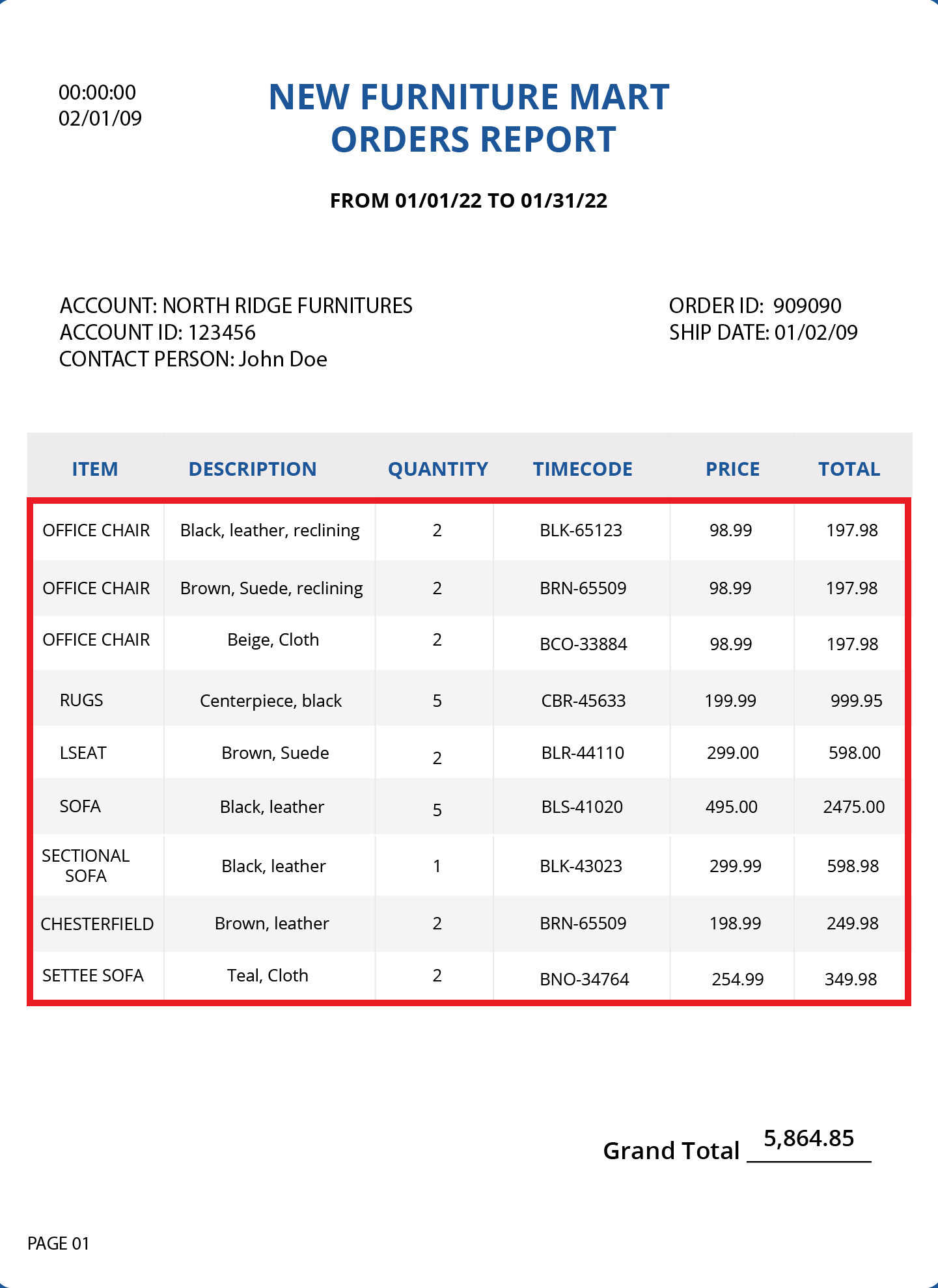
Collection data regions have a yellow icon in the Model Layout panel.
Append Region¶
Append Region is a region where the data extracted is concatenated or linked with the main data region. It is a region that you can add as part of a report model that would otherwise be left out of a data region. It can be before or after the main data region.
In the example below, the grand total can be extracted in an Append region as it needs to be concatenated with the main data region, Account. Notice that the grand total does not contain a pattern or logic like the lines containing the details of the account, therefore it needs to be in a separate append region.
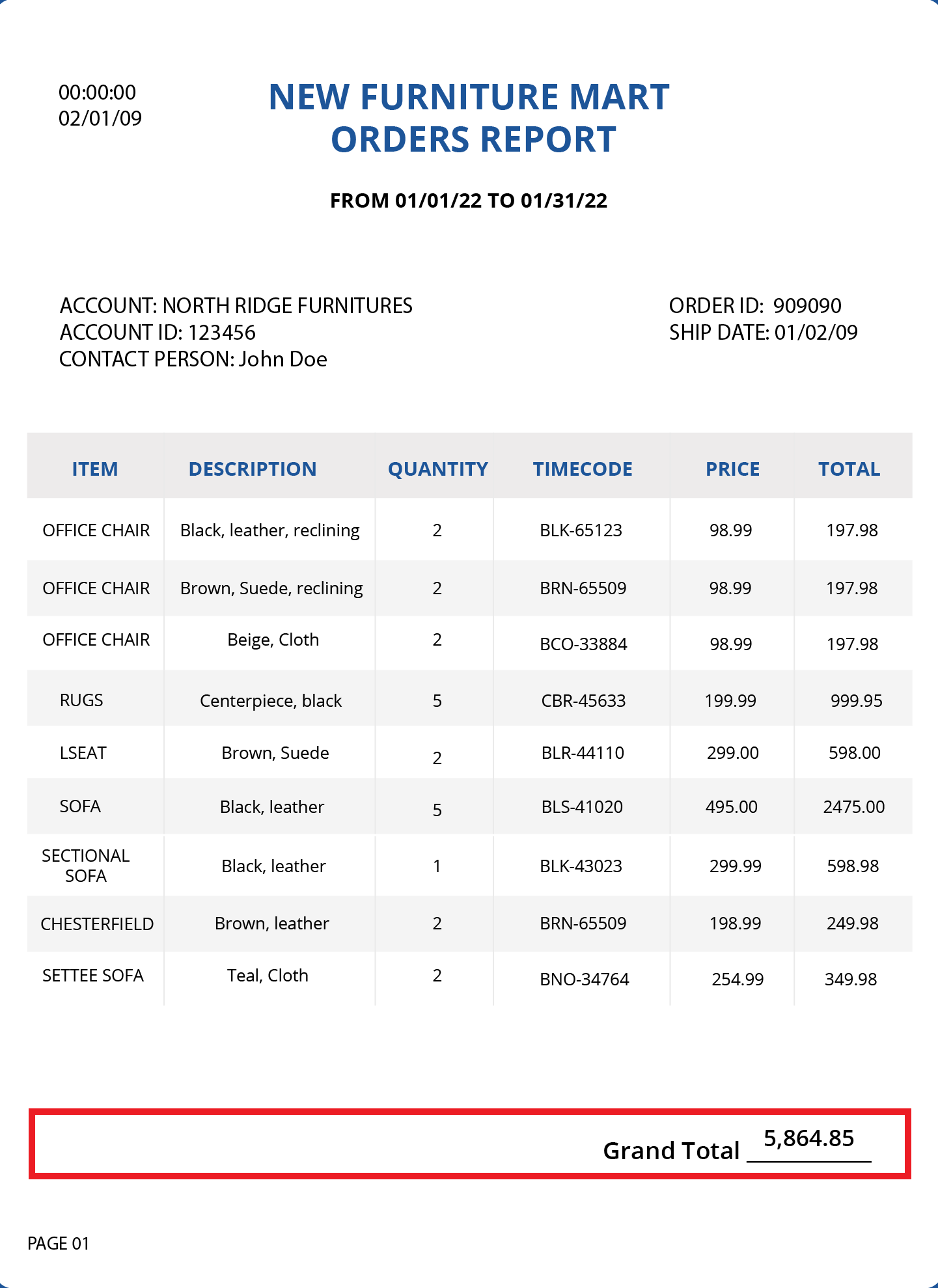
If needed, a data region can be converted to an append data region and vice versa within the Model Layout panel.
Right-click on the data region in the Model Layout panel and select the Change to Append Region option from the context menu.
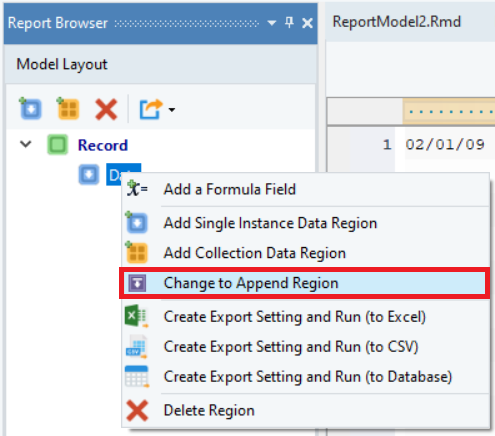
Once changed, now the Model Layout represents the node as an append region.
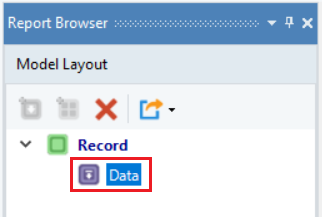
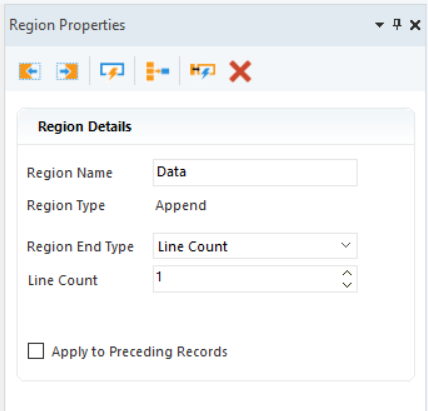
The Region Properties panel also changes to reflect the append region.
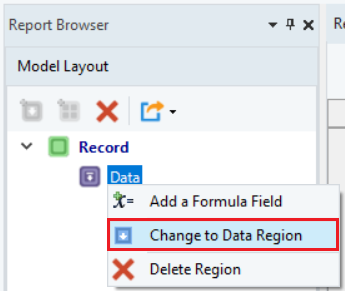
To change your append region to a data region, right-click on the append data region in the Model Layout panel and select the Change to Data Region option from the context menu.
AGL Data Regions¶
In addition to the aforementioned data regions, ReportMiner has some additional regions which are created when the layout is auto-generated using the Auto-Generate Layout (AGL) feature. The primary difference between AGL regions and other data regions is that AGL regions cannot be created manually. A user must run AGL for these regions to be created.
Table Region¶
A table data region is the first region that is created when AGL is run. A table data region contains multiple sets of data points, just like collection regions. A table region is detected based on the names of the columns of a table. In ReportMiner, column names are called headers. Users can adjust the height of the header after AGL extracts a table region to improve the accuracy of the area detected within the region.
A table region cannot be created independently or manually. It can only be created when an AGL operation detects a table in an unstructured document.
Note: Column headers in a table region are different from a header region mentioned at the beginning of this article.
Name-Entity Region¶
A name-entity region contains a single set of data points as key-value pairs. Name-entity regions are like the single-instance data regions in theory, meaning, there is a one-to-one relationship between the keys and values.
Name-entity regions cannot be created independently or manually. They are only created when an AGL operation detects key-value pairs in an unstructured document.
Data Regions Summary¶
| Region Type | Description | Can it be created manually? |
|---|---|---|
| Header and Footer | Extracts data occurring at the beginning/end of each page. | Yes |
| Single-Instance | Extracts single set of data points with a one-to-one relationship between parent and child region. | Yes |
| Collection | Extracts multiple sets of data points with a one-to-many relationship between parent and child region. | Yes |
| Append | Extracts data which needs to be concatenated with the main data region. | Yes |
| Name-Entity | Extracts area with key-value pairs. Clone of Single-Instance region. | No (AGL region) |
| Table | Extracts area which contains a table based on headers detected. Similar to collection region. | No (AGL region) |