Pattern Count¶
Pattern Count is the number of patterns that ReportMiner matches on your file to capture a data region. This is useful if more than one pattern is required to identify the beginning of your data region. You can specify up to five patterns in a report model at a time.
In this document, we will explore how the Pattern Count feature helps with the selection of a data region.
Loading an Unstructured File¶
1. Open a Report Model in ReportMiner by going to File > New > Report Model.
2. A Report Options window opens.
3. Provide the File Path for the unstructured file by clicking on the folder icon ![]()
Download the sample data txt from here.
ReportMiner supports extraction of unstructured data from text, EDI, Excel, PRN, and PDF files. In this case, we are extracting data from a text file.
There are many options available on the Report Options window to configure how you want ReportMiner to read your file. The reading options depend on the file type. For example, if you have a PDF file, you can select the scaling factor, font, tab size, and passwords.
You can read about these options here.
4. Click OK. A text file containing information regarding customer’s dues will open in the report model designer.
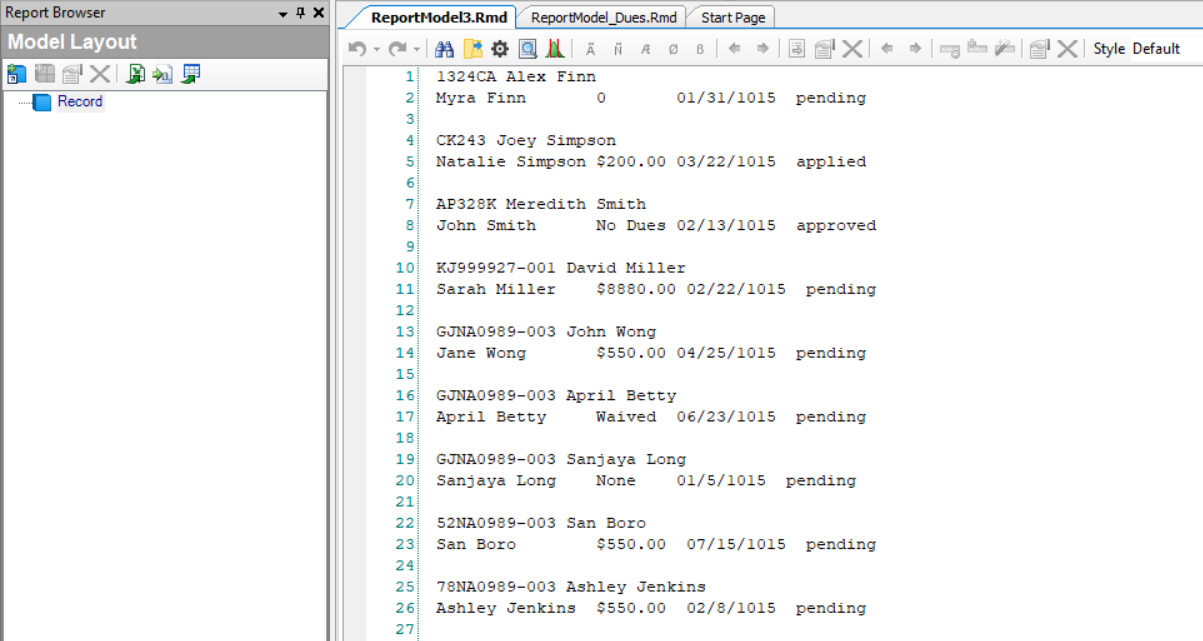
Now that the file is open in ReportMiner, we will create an extraction template.
Creating a Report Model¶
1. Right-click on the Record node in Model layout under the Report Browser panel. Select Add Data Region from the context menu.
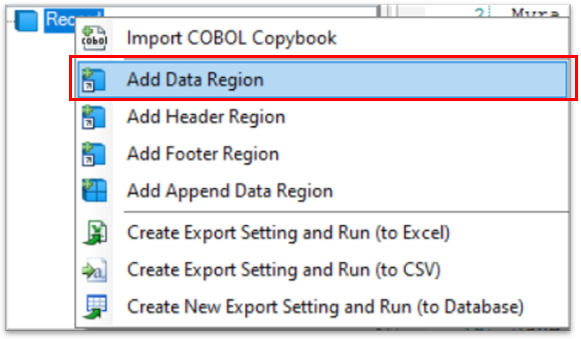
A pattern box, Region Properties panel and Pattern Properties panel is added on the Report Model designer window.
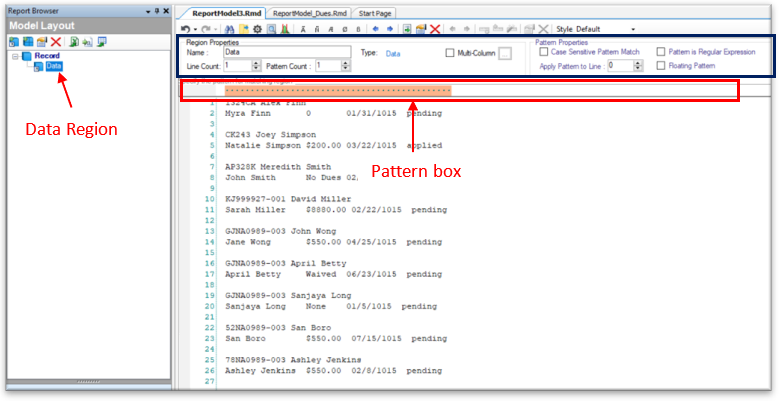
2. Specify the pattern that ReportMiner can match on your file to capture data. You can use an alphabet, character, number, word or a wild card or any combination of these to define your pattern.
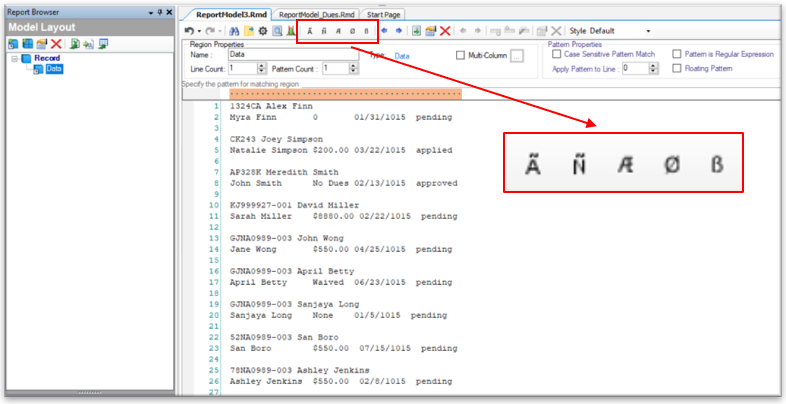
Astera ReportMiner has built-in wild cards to facilitate region selection.
| Wild Cards | Description |
|---|---|
| Ã | It matches any alphabet on the file. |
| Ñ | It matches any digit on the file. |
| Æ | It matches any alphabet or digit on the file. |
| Ø | It matches any non-blank character on the file. |
| ß | It matches any blank character such as line, space, tab etc. on the file. |
In this example, we want to capture the data highlighted in yellow. Notice that the Date provided in Line 2 follows a consistent pattern as each data block below line 2 contains a fixed date pattern.
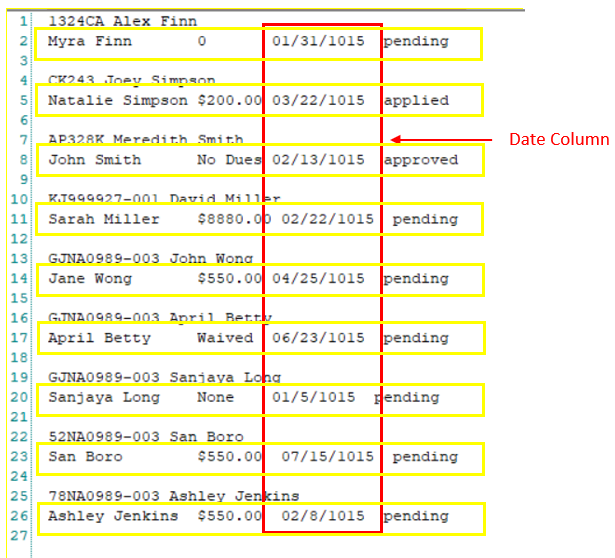
We will specify this pattern using Ñ wildcard in the pattern box. Notice that this pattern alone will not capture the complete data region containing the date column since the dates in Line 11 and Line 23 are not aligned with the specified pattern.
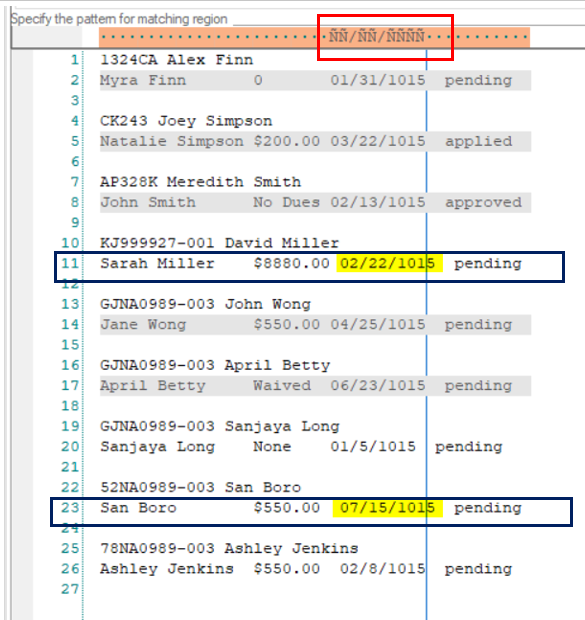
3. To handle this issue, we will select the Floating Pattern and Float Fields options inside the Pattern Properties panel on top.

Observe that the regions containing dates in Lines 20 and 26 are still not captured because the date in these lines is not aligned with the pattern and contains only a single digit for the day contrary to the date format in the rest of the regions.
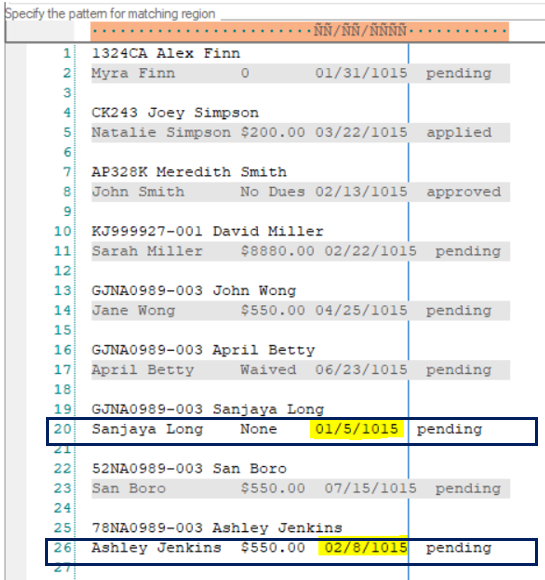
4. To capture data in these two lines, we need to increase Pattern Count to 2. Observe that a second pattern box has been added below the first pattern box.
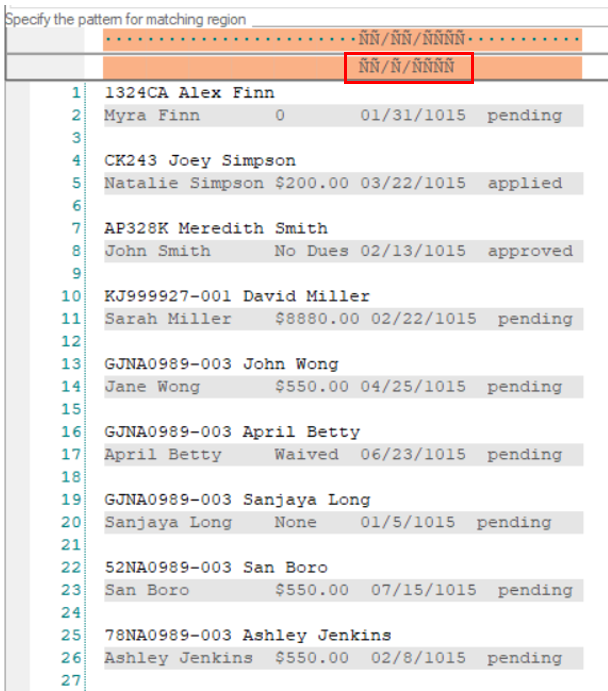
Now specify its pattern using Ñ wildcard in the second pattern box. Make sure to check the Floating Pattern and Float Fields options for this data region as well.
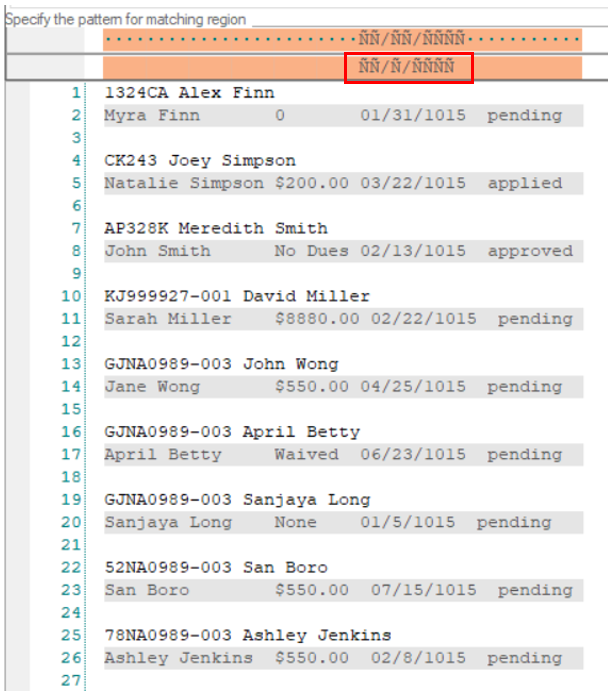
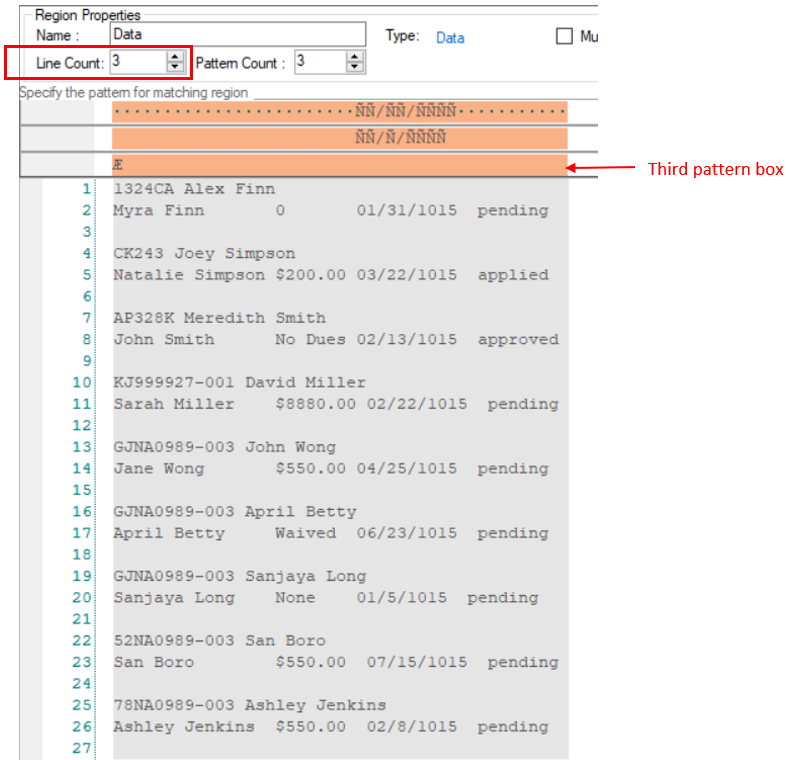
5. Increase the Line count to 3
Repeat the same process to capture the remaining data as shown in the screenshot below.
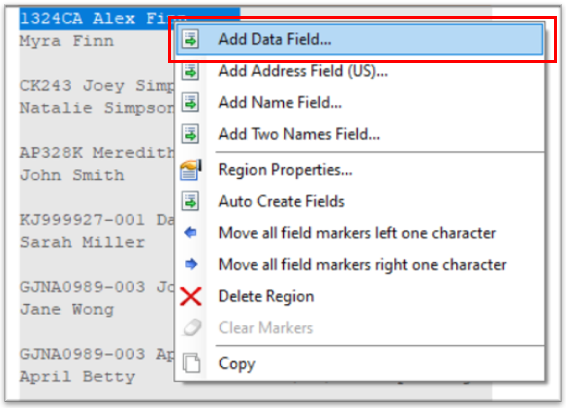
6. Once our data region is defined, the next step is to create data fields. For that, highlight each field area, right-click and select Add Data Field.
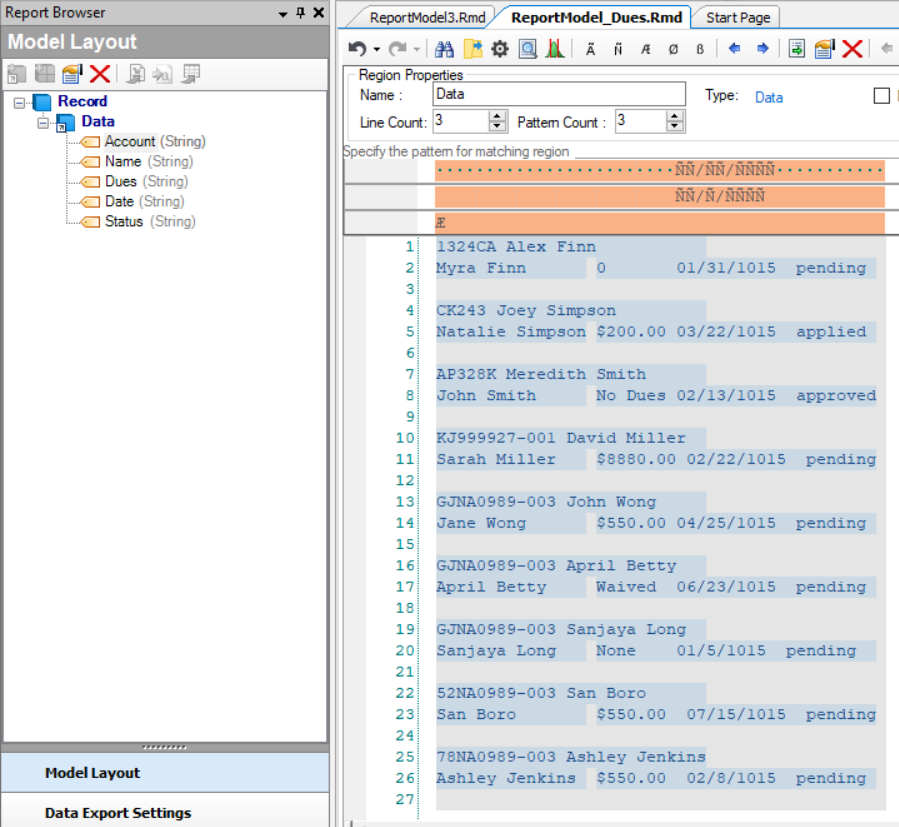
Repeat the process to create more data fields and name them as shown below.
7. Preview data by clicking on Preview Data icon ![]() placed in the toolbar at the top of the designer window.
placed in the toolbar at the top of the designer window.
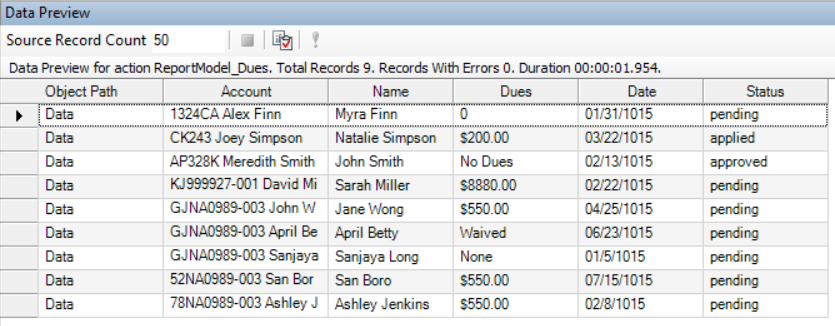
A Data Preview window will open, displaying a preview of the extracted data.