Astera ReportMiner: Performance on Different Hardware Settings and Case Complexities¶
The hardware requirements for Astera ReportMiner have been tested on the following three systems with different configurations:
- Processor: Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40 GHz 2.40 GHz, RAM: 8 GB, No of CPUs: 6
- Processor: Intel(R) Core (TM) i5-8250U CPU @ 1.60GHz RAM: 32 GB, No of CPUs: 8
- Processor: Intel(R) Xeon(R) D-2146 NT CPU @ 2.30 GHz 2.30 GHz, RAM: 64 GB, No of CPUs: 16
The two variables that generally affect the performance of ReportMiner are concurrent jobs and file size. However, case complexity may also have some part to play in special cases. We will test the time taken by ReportMiner to run each job by keeping one factor as a variable and the other facts as constant.
Let’s go over the three cases for complexity.
Case Complexity¶
Normal Complexity¶
In this scenario, we are orchestrating the process of extracting data from an unstructured PDF file that contains the proof of loss of an emergency management agency.
Use Case¶
In the case of normal complexity, we have applied some validation checks on the incoming data from a Report Source that contains the dimensions of the rooms to ensure that all the dimensions are in the ‘Real’ data type before writing it to a database destination.
High Complexity¶
In this scenario, we are orchestrating the process of extracting data from an unstructured PDF file. The source file contains the proof of loss of an emergency management agency. However, this time, instead of one, we have used two report models to extract the required data from the PDF file. Hence, there are two Report Source objects in the dataflow. The complexity of the process has increased due to the higher number of sources and the additional steps required for data scrubbing, aggregation, and sorting.
Use Case¶
In the case of high complexity, the source data is in a hierarchical format and is coming from two Report Source objects. The purpose of using two Report Source objects is to cater to the complexity that may have occurred if a single source was used considering the nature of the data fields which we are extracting. We have transformed the data by applying relevant transformations while retaining its hierarchical structure using the Passthru transformation to avoid any cardinality issues. The datasets from both the sources are then joined using the Join transformation where it is flattened and loaded into a database destination.
Very High Complexity¶
In this scenario, we are orchestrating the process of extracting data from an unstructured PDF file that contains an insurance report of a maintenance company. The complexity of this process is very high since the dataflow contains six subflows and each subflow contains four Report Sources. Hence, we are extracting data from 24 Report Sources altogether and then loading it to a database destination after applying the relevant transformations to it.
Use Case¶
In this case, we have six subflows and each one of them has the entire logic of data extraction encapsulated in it. We are extracting the data using a Report Source object. This data is further sorted and summarized and written into a Subflow Output.
In the dataflow, these Subflow objects are triggered, further transformed, and joined into a single dataset to be written to a database destination.
Factors Affecting ReportMiner’s Hardware Performance¶
1. Concurrent Jobs¶
Below are observations for each hardware configuration when we run 5, 10, 15, and 20 jobs in parallel while keeping the file size constant. You can see that as the number of CPU increases, the runtime of the job decreases. However, it is important to note that the runtime may also vary depending upon the case complexity but not up to a noticeable extent.
Let’s observe how the runtime of jobs varies as the number of concurrent jobs increases with the help of a graph.
In the graph:
| On x-axis | No. of Concurrent Jobs |
|---|---|
| On y-axis | Time Taken to Execute the Concurrent Jobs |
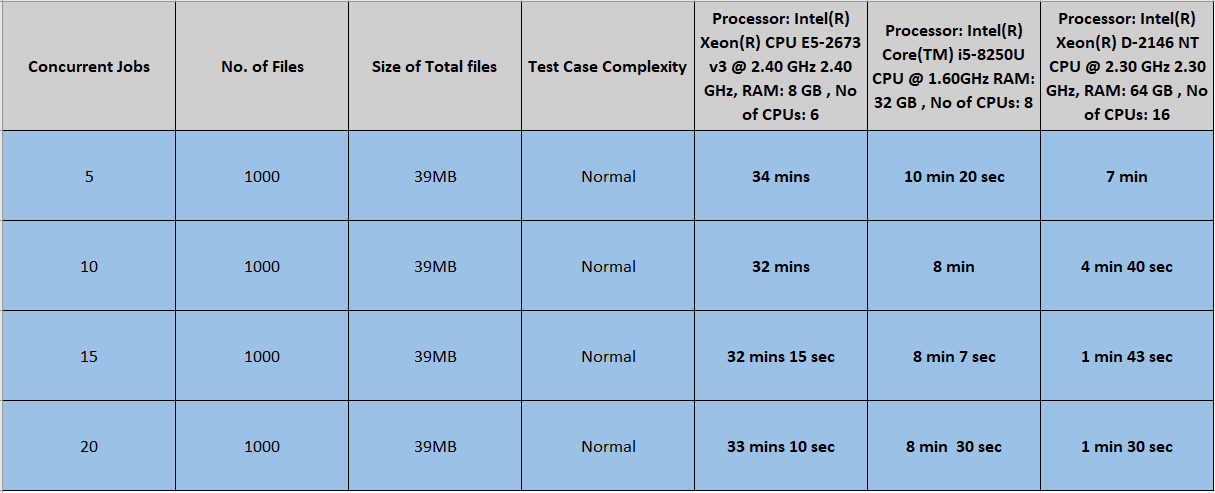
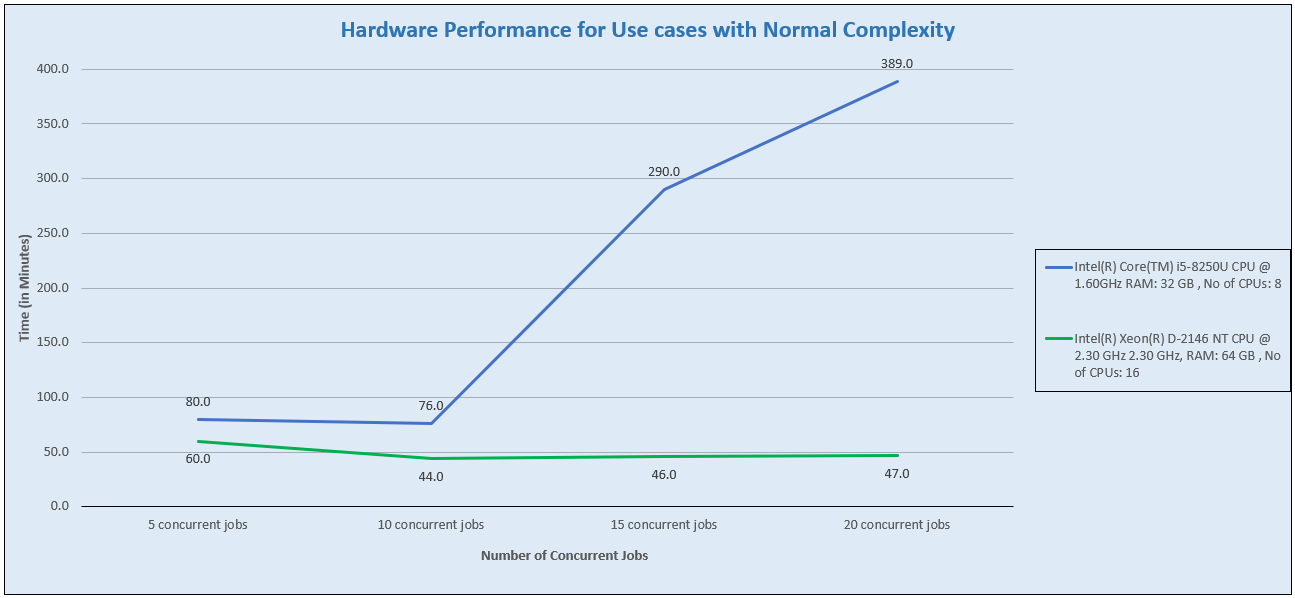
(a) The runtime of 5, 10, 15, and 20 concurrent jobs when the case complexity was kept normal:
Readings:
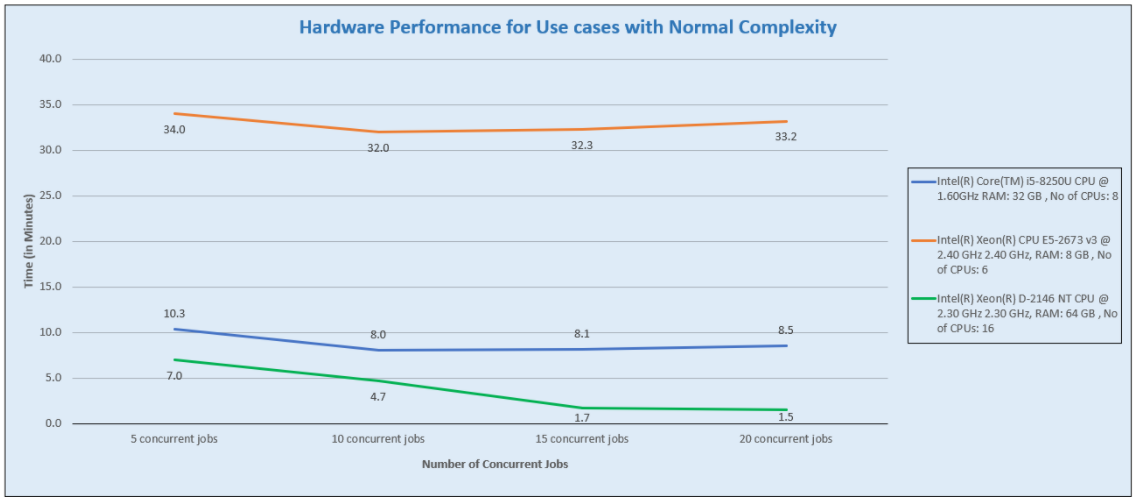
Graph:
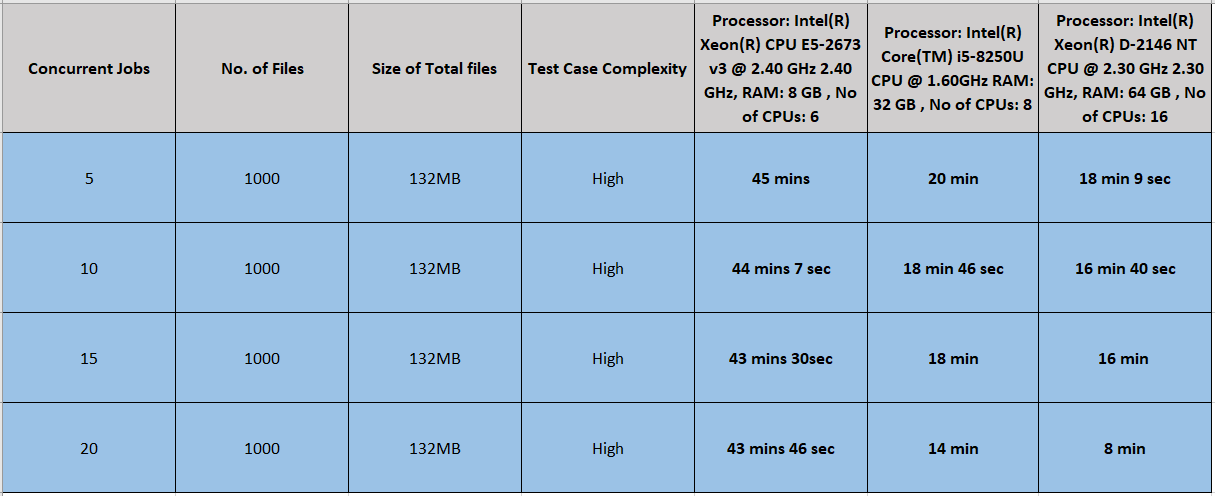
(b) The runtime of 5, 10, 15, and 20 concurrent jobs when the case complexity was kept high:
Readings:
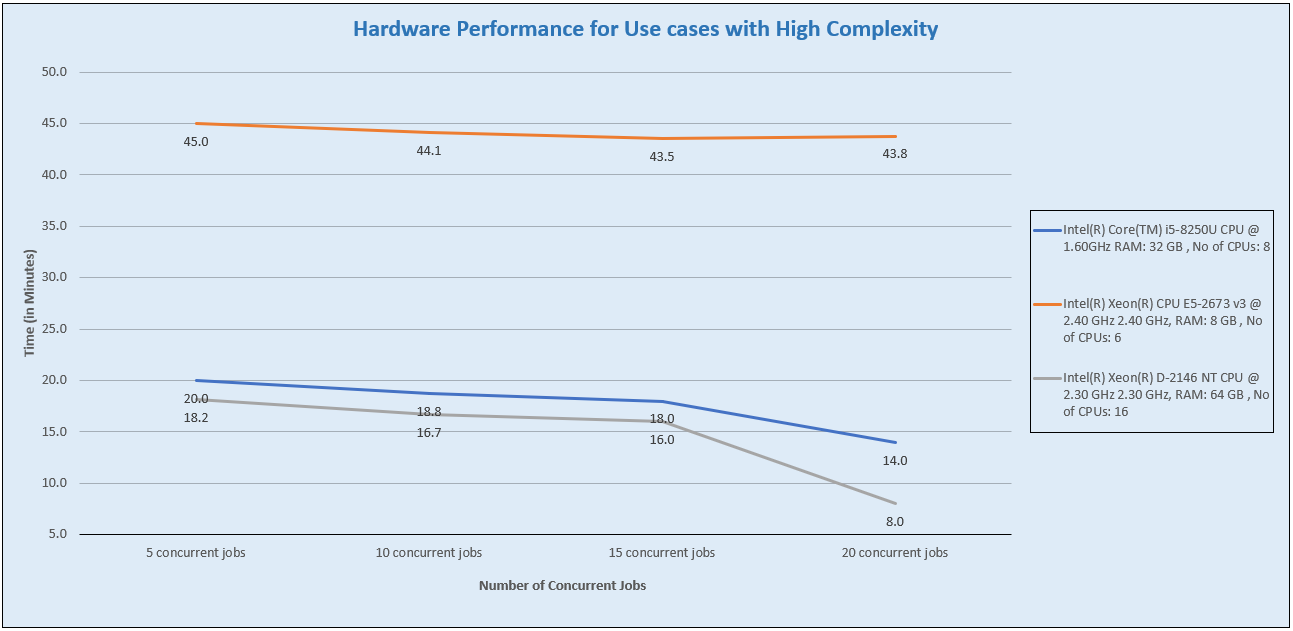
Graph:
(c) The runtime of 5, 10, 15, and 20 concurrent jobs when the case complexity was kept very high:
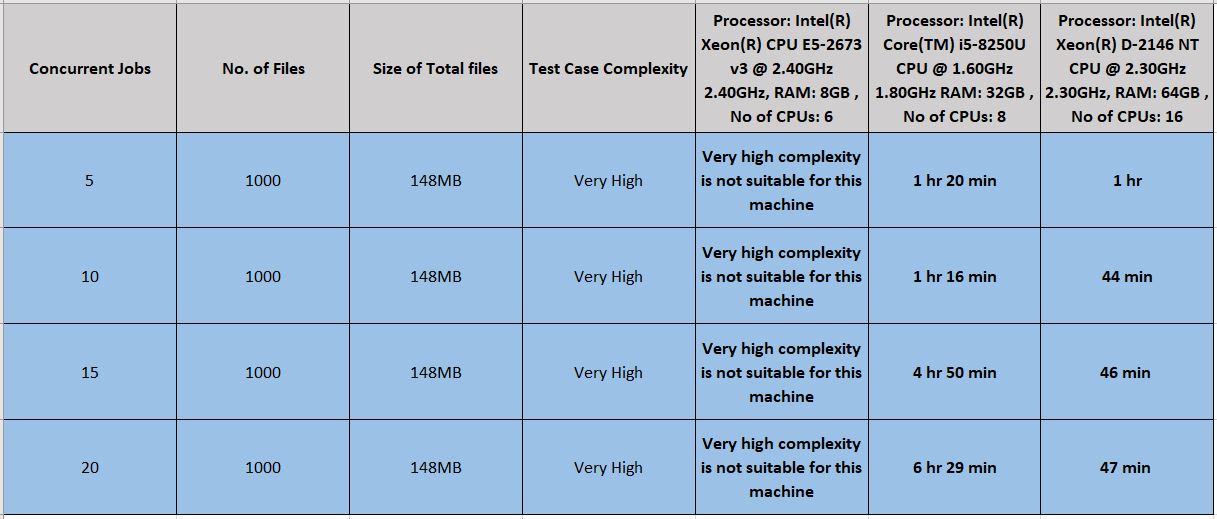
Graph:
Note that, the file size varies due to the increased complexity in the above three cases. However, as stated earlier, it does not have a noticeable impact on the runtime.
2. File Size¶
Below are the observations taken by three different file sizes while keeping the number of concurrent jobs constant. You can observe that as the file size increases, the time taken to run the jobs increases.
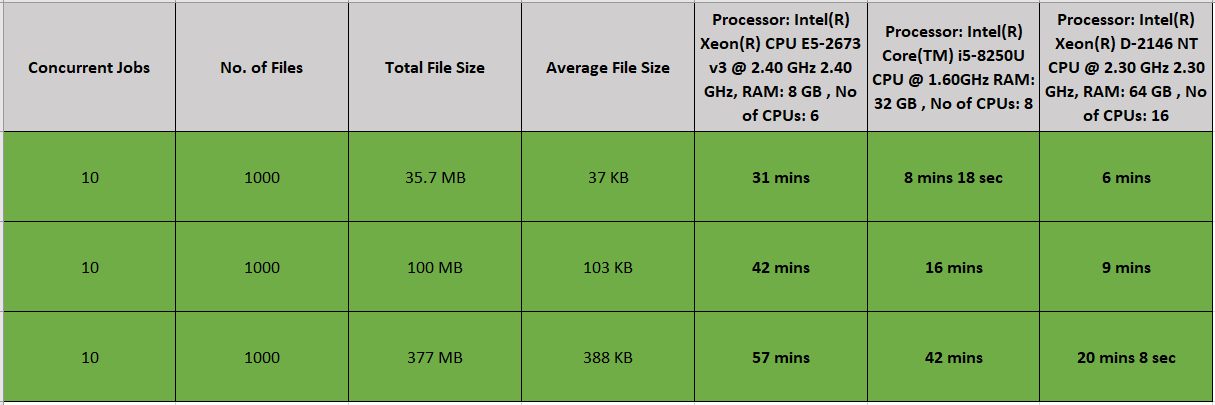
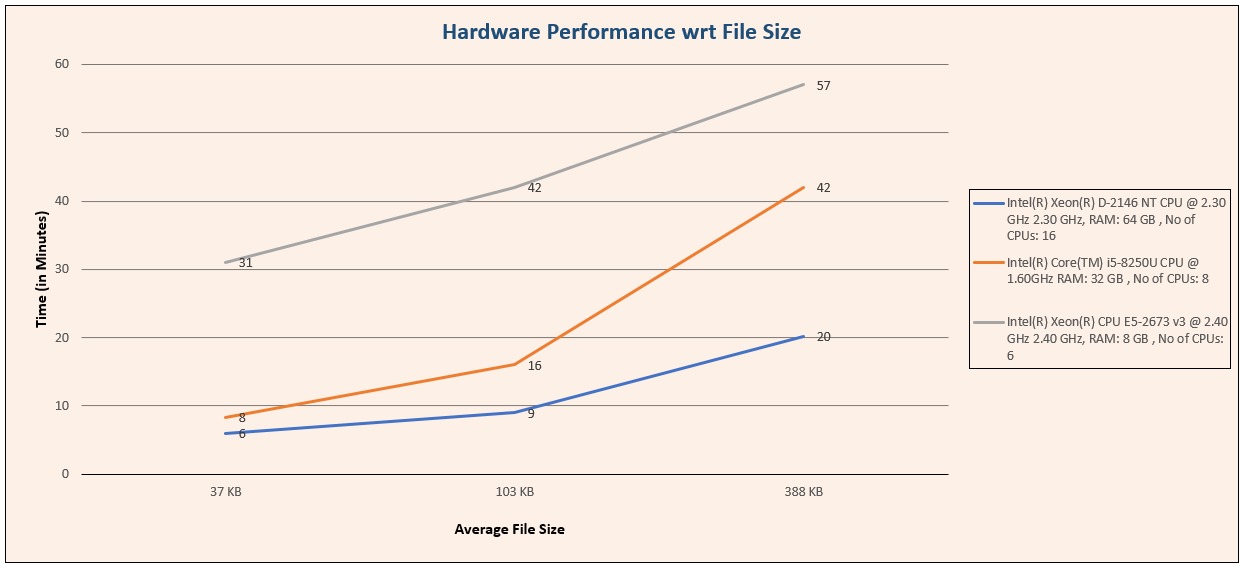
Let’s understand this with the help of a graph.
In the graph:
| On x-axis | Average File Size |
|---|---|
| On y-axis | Time Taken to Execute Them |
This concludes the summary of ReportMiner’s performance on different case complexities and hardware settings.