Field Properties Panel¶
In this document, we will discuss the Field Properties Panel and various options it offers in Astera ReportMiner. But first, let us briefly discuss the concept of data fields.
What is a Data Field?¶
A Data Field is the area within a data region containing the extracted information. It captures data points and writes them as elements of a field.
Data fields together with data regions constitute the schema for extracting information from unstructured source files.
Field Properties Panel¶
Once a data field is added within a data region, a Field Properties panel will appear right above the designer, providing options for basic configuration settings.
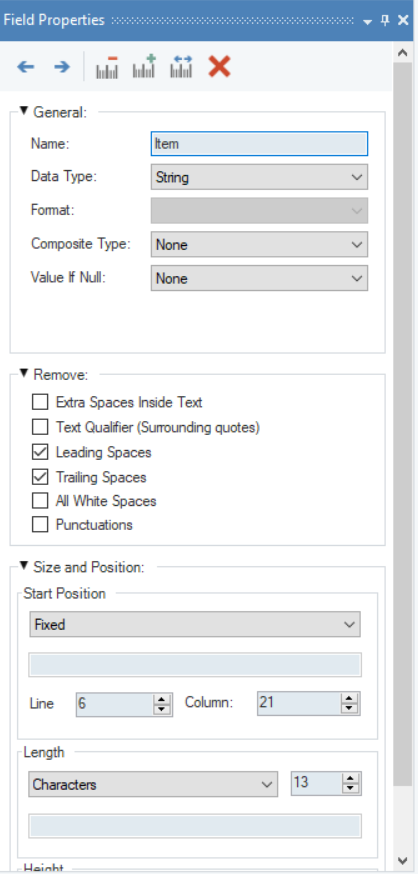
The Field Properties panel allows user to customize the captured data fields with the help of the following options:
Field Properties toolbar¶
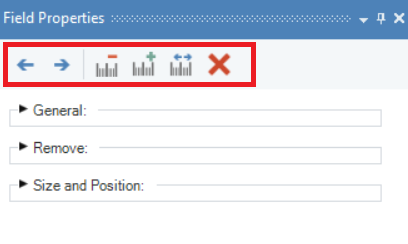
Move field marker left one character – this option moves field marker towards left by one character.
Move field marker right one character – this option moves field marker towards right by one character.
Decrease field length by one character – this option allows user to decrease the field length by one character.
Increase field length by one character – this option allows user to increase the field length by one character.
Auto determine field length – this option allows user to determine the length of selected data field automatically.
Delete field – this option deletes the selected data field.
General¶
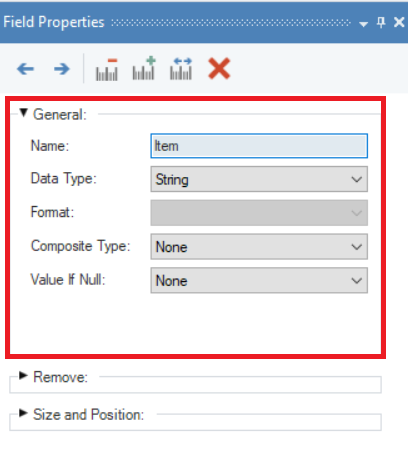
Name – Allows user to assign a name to a data field. You can type in any name depending on the content of the extracted data points. The assigned field name must be unique and without spaces in between.
Data Type – Provides the option to specify the data type of the field such as string, real, date, etc.
Note: The data type of every data field appears next to the field name in the Model Layout tab.
Format - Allows user to change the format of a date field.
Composite Type - Resolves a composite field such as full address or full name into parsed components.
Composite data contains details about a record that can be further split into smaller elements. For example, a record about a customer transaction might contain a date field. Date fields are processed by a built-in parser that splits the date into hour, day, month, year etc.
Value If Null - Performs action in cases where the extracted field value is null.
- None – This is the default setting. If None is selected, no action is taken to replace the value in an empty cell. For example, if the field in question (Item field) has some null records, the cells within the field are displayed as empty in the preview.
- Apply Specified Default – A specific string value can be assigned in case the extracted data point is null. When the program finds a null value, the specified value will appear in the output instead of an empty cell.
- Use from Previous Record – Returns the value of the previous record in the same data field.
Remove¶
You can find some additional options for data cleaning in this section.
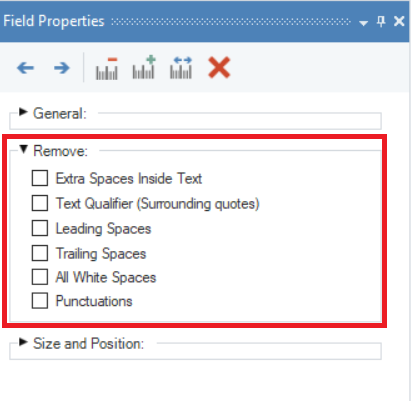
Extra Spaces Inside Text - removes extra blank spaces inside the source document’s text. This is most helpful for cases like fixed-length files, where there may be many extra spaces between characters.
Text Qualifier (Surrounding quotes) - removes quotation marks from your data. This is especially useful for .csv files with many quotation marks as it converts them into an easier-to-manipulate format. For example, “John Schmidt” would be extracted as John Schmidt.
When this option is left unchecked, the quotation marks surrounding text will be retained in the extracted data.
Leading Spaces - removes/trims all blank spaces before the first non-blank character appears in a data field.
Trailing Spaces - removes/trims all blank spaces after the last non-blank character in a data field*.*
All White Spaces – removes all the white spaces from a data field
Punctuations – removes all the punctuations from a data field
Size and Position¶
In this section, you can specify the size and position of a data field.
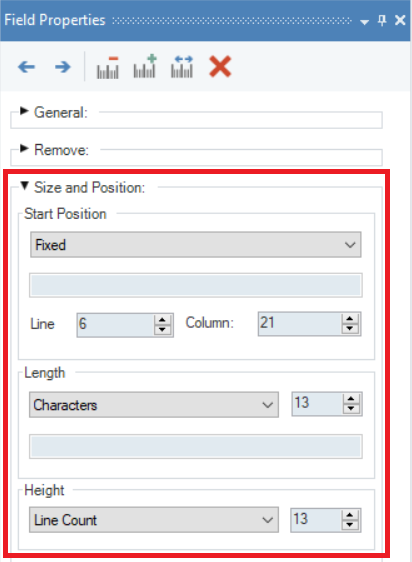
Start Position - allows users to manually specify the start position of a data field.
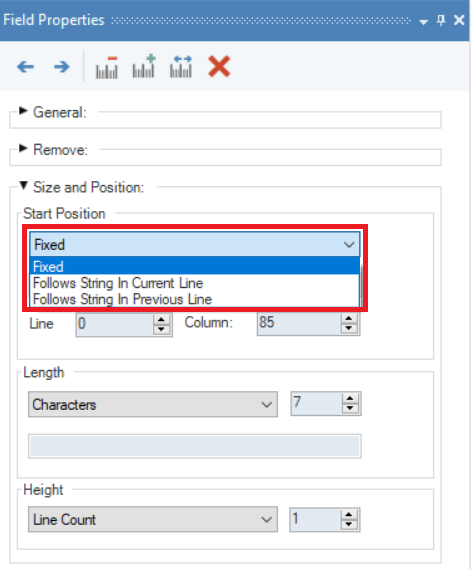
- Fixed – this will set the position of a data field to start from where you select the data field while capturing it.
- Follows String in the Current Line – this will set the position of a data field to start after a specified string in the same line.
- Follows String in the Previous Line – this will set the position of a data field to start after a specified string in its preceding line. For example, if in a file containing medical records, every set of patient data started with “Patient Information” above it, ReportMiner will set the field to begin the line after “Patient Information”. This way, all information relevant to each patient record will be captured.
Line/Column – There is an invisible grid with coordinates that overlay every report model. These coordinates can be used to specify the start position in a report model by referencing a single point on a data field. The values for Line and Column can be found at the bottom-right corner of the report model when a point on the file, opened in the designer, is selected.
Length - This menu allows users to set the length of a data field. You can select from the following options:
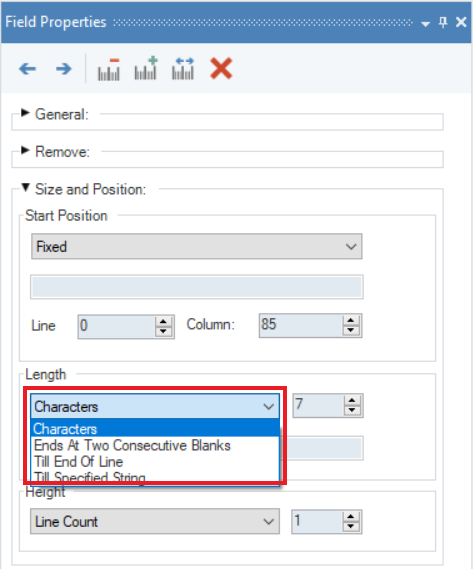
- Characters – allows users to set the length of a data field up to a certain number of characters. For example, if the value for this option is set to 5 for a data field, James123 will be extracted as James.
- Ends at Two Consecutive Blanks – ends a data field once it reaches two consecutive blank characters.
- Till the End of the Line – ends a data field on the last character in the line.
- Till Specified String – ends a data field once it reaches a specified string, such as “Report End”. This option works like the Start Position-After String options as it ends a data field on a specified string.
Height - This menu allows users to set the height of a data field. You can select from the following options:
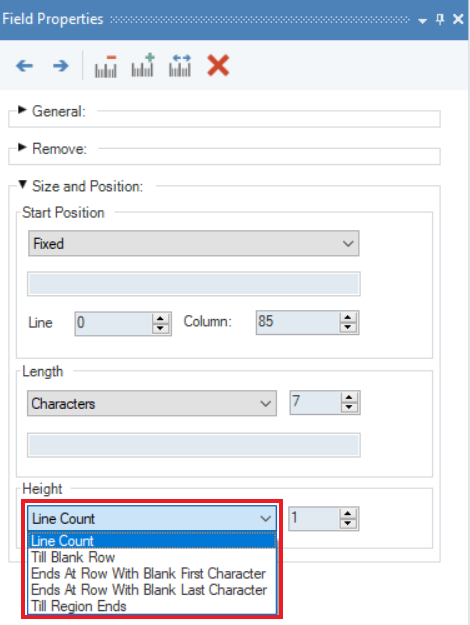
- Line Count – set the height of the data field to a certain number of characters.
- Till Blank Row – ends a data field once a blank row is reached.
- Ends at Row with Blank First Character – ends a data field once it reaches a row with a black first character (a space).
- Ends at Row with Blank Last Character – ends a data field once it reaches a row with a blank last character (a space).
- Till Region Ends – the data field continues till the end of its data region. It determines the height of a data field based on the height of the data region. The default setting of data fields, especially ones that vary in height, is to measure them by line count.